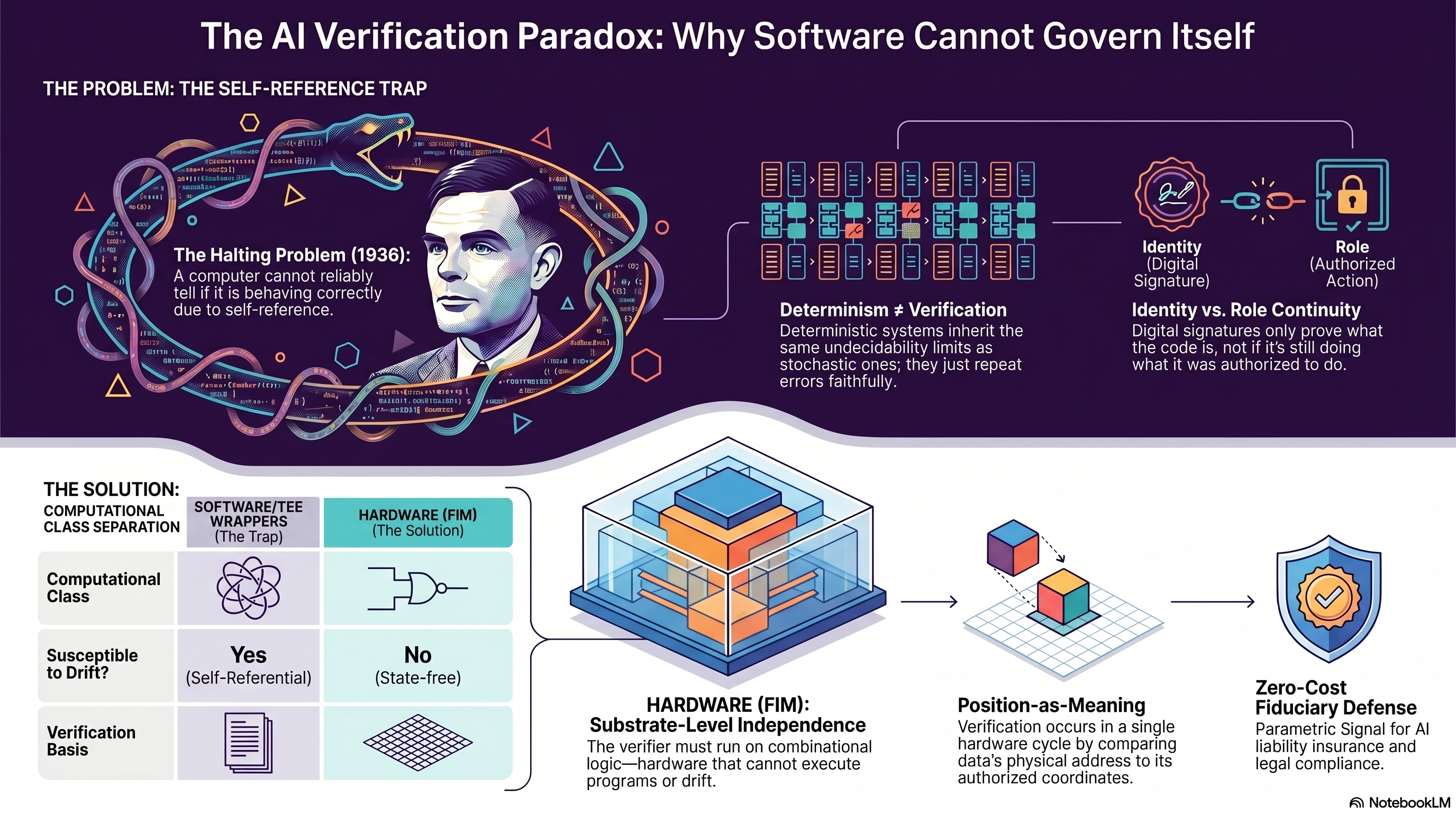
The whole argument in one frame: software oversight inherits the regress; hardware substrate-level role continuity escapes it. (NotebookLM)
A
Loading...
🪞Who This Is For
This post is written for the people who sign the deployment.
Not the engineers. Not the vendors. The CIO approving the procurement. The CRO approving the risk register. The general counsel approving the compliance memo. The board member approving the AI governance policy. The fund partner signing the allocation.
If you are in any of those seats, a claim is going to be made to you, probably by a confident and technically credentialed person, that sounds reasonable and is wrong. It will sound like: "our inference is deterministic, so the halting problem doesn't apply." Or: "our policy layer maintains behavioural continuity over time, so runtime verification is complete." Or: "our cryptographic attestation makes the output independently verifiable."
Each of these claims passes the surface test. Each one fails the structural test. And the structural test is the one your regulator, your carrier, and eventually your court are going to apply.
This post gives you the test.
You don't have to be a computer scientist to apply this test. You have to ask one question: does the mechanism that's supposed to catch the problem run on a substrate that can have the problem? If yes, it cannot catch itself. If no, specify what it runs on. That is the whole argument, in one question.
🪞 A → B 🔬
B
Loading...
🔬The First Principle: A System Cannot Prove A Property Of Itself
In 1936, Alan Turing proved something that sounds abstract and is not. He proved that no general machine can decide, for every input, whether an arbitrary program will halt. The proof uses a specific structural move called diagonalization. The move constructs a machine that asks itself whether another machine — built from its own specification — would halt. If the answer is yes, the constructed machine loops forever. If the answer is no, it halts. Either answer contradicts the decision procedure that was supposed to be deciding.
The proof is not about randomness. It is not about unpredictability. It is not about stochastic output. It is about self-reference.
Any sufficiently powerful system (technically: any Turing-complete system) contains descriptions of itself. When such a system tries to decide a property of itself, the decision procedure must, somewhere in its operation, reference its own description. That reference is the diagonal that makes the proof work.
Kurt Gödel proved the same structural result in mathematical logic, for the same reason. Henry Rice extended it: any non-trivial semantic property of a Turing-complete program is undecidable. You cannot write a program that, for arbitrary inputs, reliably decides whether another program has some specific meaning-level property.
In plain English: a computer cannot look at itself and tell you whether it is behaving the way it was supposed to be behaving. Not because the answer is random. Because the answer requires self-reference, and self-reference is where decidability fails.
Turing's 1936 paper is available for free. So is Gödel's 1931 paper. So is Rice's 1953 theorem. These are not contested results. They are the foundations of computability theory. If someone tells you "the halting problem doesn't apply to our system because we are deterministic," they are either unfamiliar with the proof or counting on you to be. Either is disqualifying for a claim this load-bearing.
The same proof, walked through the engineering layers: Halting Problem → Identity vs Role → Hardware FIM as the substrate-independent verifier. (NotebookLM)
🪞🔬 B → C 💡
C
Loading...
💡Deterministic Behaviour Is Not Determinism
The most popular current dodge is this: "Our inference is deterministic — same weights, same inputs, same output. Therefore there is no stochastic failure mode. Therefore the halting problem doesn't apply. Therefore verification is complete via re-execution."
This claim is wrong in a specific and important way. Let's walk it.
Determinism is a property of the transition function. A Turing machine is deterministic by definition — given a state and an input, the next state is fully specified. Alan Turing's proof of undecidability applies to deterministic machines. It is the baseline, not the exception. Halting is undecidable for deterministic machines precisely because the undecidability is about self-reference, not about randomness. A deterministic Turing-complete system verifying itself inherits exactly the same limit as a stochastic one.
Deterministic behaviour at runtime is not the same thing. Repeatable output under controlled inputs is a property that says nothing about whether the system is still doing what it was authorized to do. It says only that, if you pin all the inputs, the outputs repeat. That is useful for debugging and for reproducibility. It is not useful for verification of functional role over time.
In any deployed AI system, the inputs are not pinned. They accumulate. Context windows grow. Tool-use outputs feed back as inputs. Retrieval layers return different documents from one run to the next as the underlying corpus changes. Prompt injection modifies the effective input before the model ever sees it. Fine-tuning updates weights. RLHF revisions change the baseline. None of these are stochastic in the probability-distribution sense. All of them break the "same inputs" condition that deterministic inference depends on.
Deterministic inference on drifted inputs produces deterministically wrong outputs. Re-running the same inference gets you the wrong answer twice. That is not a verification success. It is faithful reproduction of a corrupted functional state.
The subtle error: "Deterministic" describes the inference. "Delegable" — meaning you can rely on it — requires that the inputs to the inference have not moved. In any real deployment, the inputs move. The deterministic wrapper around drifting inputs produces deterministic wrongness. You did not verify; you only reproduced.
So when someone says "we are deterministic, therefore we escape the regress," they are conflating two different properties. The technical property (transition function is deterministic) does not imply the verification property (the system can certify its own functional role over time). One is about the math of the machine. The other is about the math of self-reference. Determinism is orthogonal to self-reference, and the halting problem is about self-reference.
A system with deterministic transitions, verifying itself, inherits the exact same undecidability as a stochastic one. The randomness is not the problem. The self-reference is.
🪞🔬💡 C → D 🧭
D
Loading...
🧭Role Continuity Sits Below Identity
Here is the second confusion, and it is deeper than the first.
Many verification proposals target identity: a hash of the weights, a signed model card, a cryptographic attestation of the binary. If the hash matches, the reasoning goes, the system is what it says it is.
Identity in this sense is cheap. It tells you what the bits are. It does not tell you whether the bits are still performing the function they were authorized to perform. A system can have a valid hash and still drift behaviorally. Weights can accumulate fine-tuning updates while the top-level hash changes in a way that's recorded as "authorized update." A policy document can be signed and also be structurally inadequate for what the deployment is now doing. Identity answers what. It does not answer whether what you have is still doing what you trusted it for.
Role continuity sits below identity. Role is the relationship between what a thing does and what it was trusted to do. If the role is intact, the thing is still trustworthy regardless of how the identity has been updated. If the role has drifted, the thing is no longer trustworthy regardless of how pristine the identity signature is.
This is the question any regulator, any carrier, and any court will eventually ask: is the thing producing this output still performing the functional role it was authorized to perform? Not: is the code signed. Not: is the model card accurate. Not: is the version number current. But: is the function intact.
In Can I Keep Trusting You?, we walked this distinction in the grammar of relationships. Every relationship that matters runs a continuous role-continuity check in the background of attention. When it fails, you notice. Role continuity is the question; identity is one answer you can run to try to approximate it, and it is an answer that does not generalize.
Nick Mabe named this from the defense-sector side in the LinkedIn thread that anchored this argument: "hashes only ever give you tamper-evidence, not continuity." A hash tells you the bits have not been tampered with. It does not tell you the bits are still performing the role you authorized. Tamper-evidence is not continuity-evidence.
If role is what needs verifying, and role is about the relationship between authorized function and current function, then the verifier must measure that relationship directly. Hashing the bits, signing the output, or checking the version string are all upstream of the question. They answer a different question.
🪞🔬💡🧭 D → E 🎯
E
Loading...
🎯The Test: Does The Verifier Execute Arbitrary Programs?
Here is the question you carry into every conversation with every vendor, every consultant, every compliance framework, every governance layer, every attestation service. It is one question. It is the only question that matters at the architectural level.
Does the mechanism that is supposed to catch the problem run on a substrate that can execute arbitrary programs?
If yes: it is Turing-complete. It can, in principle, exhibit any of the failure modes the thing it was supposed to catch can exhibit. It inherits the regress. It cannot reliably verify a property of itself or of anything in its own computational class.
If no: specify what computational class it runs in. If the answer is a lower class — combinational logic, finite-state automata, fixed-function comparators — the verifier is structurally incapable of exhibiting the failure modes it is meant to detect. That is what independence means.
This is not a sophisticated test. It has two possible answers. Most claimed solutions give the first answer and hope you don't notice.
A governance software dashboard runs on Turing-complete substrate. It inherits. A cryptographic attestation chain runs Turing-complete verifier software. It inherits. A TEE — Trusted Execution Environment on Intel TDX, AMD SEV-SNP, or NVIDIA Confidential Computing — runs arbitrary programs inside the enclave. It inherits inside the enclave; the isolation is from outside observers, not from self-reference. A policy engine over symbolic state runs a Turing-complete rule evaluator. It inherits. A human-in-the-loop compliance reviewer uses software tools to review. The tools inherit. The reviewer's attention is not a substrate. A formal verification suite proves decidable properties. The undecidable ones — most of what matters in runtime drift — are out of scope by construction.
And on the other side: a combinational logic comparator that tests whether a data element's physical address matches its rank-computed address does not execute programs. No program counter. No branch. No loop. Cannot hallucinate. Cannot drift. Is not subject to the halting problem because it is not in the class of systems the halting problem applies to.
That is the distinction. That is the whole distinction. Everything else is detail.
The market currently conflates "hardware" with "the computational-class distinction." A GPU is hardware. A GPU is Turing-complete. A GPU does not escape the regress. The boundary is not silicon vs software. The boundary is combinational logic vs instruction execution. Different chips, same class. Different class, possibly same chip.
🪞🔬💡🧭🎯 E → F 🧱
F
Loading...
🧱Seven Orthogonal Paths To The Same Conclusion
The self-reference argument is not the only way to reach the conclusion that runtime role verification requires a substrate in a lower computational class. It is the most fundamental. But seven independent paths converge on the same answer, which is what tells you the conclusion is load-bearing.
Path 1 — Computability theory. Turing 1936. Gödel 1931. Rice 1953. A system cannot decide non-trivial properties of itself or of other systems in its computational class. The mathematics is settled. Anyone claiming to have built a Turing-complete verifier of Turing-complete systems is claiming to have solved an 89-year-old impossibility result. That claim is available for examination; it has not been produced.
Path 2 — Input-plane drift. Even a deterministic inference layer depends on inputs that are not under deterministic control. Context accumulation, tool-use feedback, retrieval shift, prompt injection, fine-tuning updates. Drift lives in the input plane. A verifier that only checks the inference against a policy cannot catch drift in the inputs that feed the inference. The input plane is where role continuity either holds or fails, and the input plane is where the substrate-level mechanism operates.
Path 3 — Regulatory. Article 14 of the EU AI Act requires overseers to "correctly interpret" the output of high-risk AI systems and "detect anomalies." Correct interpretation presupposes that the thing producing the output is still the thing that was authorized. Without a mechanism that measures this continuously, the oversight obligation is legally unsatisfiable. We walked this in The EU AI Act Was Written To Be Impossible in Software. The regulatory forcing function is not a theoretical concern; August 2, 2026 is when it becomes enforcement-ready.
Path 4 — Actuarial. Insurance carriers underwrite signals, not narratives. SOX clears on auditor signals. CAT bonds clear on parametric triggers. Cyber clears on breach-notification signals. Each market was built because a signal became measurable. AI liability insurance is currently at zero dollars globally because no signal exists at the substrate. A policy framework without a substrate signal is, actuarially, a narrative. Narratives are not priced. Without insurability, deployers are carrying the liability personally, on every inference.
Path 5 — Legal precedent. Independence as a regulatory concept is not native to financial regulation, despite the popular framing. It is native to every regime that separates an audit function from the thing being audited — product safety (Notified Bodies), medical device regulation (independent test bodies), aviation safety (DO-178C), financial audit (SOX, Dodd-Frank, MiFID II). Across regimes, independence is defined the same way: the auditor cannot share failure modes with the audited entity. A Turing-complete audit layer shares failure modes with Turing-complete AI. It is, under the operative legal definition, not independent. See Can I Keep Trusting You? for the Notified-Body analog.
Path 6 — Engineering parsimony. Every upstream "governance wrapper" or "policy layer" or "admissibility framework" proposed as a substitute for substrate-level verification is itself a computation. A computation maintaining stability over time on a Turing-complete substrate accumulates boundary-crossing cost at the same rate as the system it governs. The stabilizer needs a stabilizer. Turing's infinite regress. This is not a new problem; it is the reason engineers in adjacent fields use memory geometry and hardware-enforced boundaries for anything that must hold under adversarial runtime conditions.
Path 7 — Market precedent. The 2008 credit default swap crisis turned on a definitional reclassification: "swap" rather than "insurance," which made "insurable interest" inapplicable and opened the door to synthetic and naked positions. The same pattern is available to AI governance: reclassifying "independent verification" as "policy compliance with organizational independence" lets current tooling claim it satisfies the requirement. Carriers cannot price that claim because no measurement exists at the substrate. Deployers carry unmeasured liability, exactly as CDS counterparties did before the crisis. The parallel was named by a credentialed risk practitioner in the LinkedIn thread; we extended it in our reply to Donald Presnell.
Each of these paths is independent. Each arrives at the same conclusion. That is what tells you the conclusion is structural, not rhetorical.
🪞🔬💡🧭🎯🧱 F → G ⚙️
G
Loading...
⚙️What Closes The Regress
A mechanism that closes the self-reference regress must, by construction, not be in the same computational class as what it verifies. Not a different chip, not an isolated enclave, not a signed binary, not a trusted compiler. A different computational class.
The filed mechanism is specific. Position encodes functional role. Each data element has a physical address determined by its position in a hierarchical semantic structure. The authorization — meaning this data is authorized to perform this function at this coordinate — is the coordinate itself. There is no separable policy object. There is no rule document. There is no stabilised frame held by a second layer. The geometry of the memory is the rule.
Verification is one combinational logic operation: bitwise XOR between the address at which the data currently resolves and the address determined by its rank-computed position. When the two match, the data is at its coordinate and the role is intact. When they do not, the displacement is quantified by the same operation that detected it. Detection and correction vector in one step, in a single hardware cycle, with no program counter, no branch, no loop, and no state to mutate.
The AI, which runs on instruction-executing hardware, can read the result of the comparator. It cannot write the mechanism. It cannot influence the geometry. It cannot drift into the verifier because the verifier has no instruction set to drift into. This is what independence as an architectural property looks like. Not "isolation" in the confidentiality sense. Not "attestation" in the cryptographic sense. A computational-class separation that makes the regress structurally impossible.
From the NotebookLM source "Hardware Verification for the AI Act":"The architecture moves the compliance question out of the substrate that can fail the test and into a substrate where the test resolves in the same cycle as the access. Cache miss is the signal. The signal is not reconstructed from partial data; it is the data, at the moment the fetch resolves."
🪞🔬💡🧭🎯🧱⚙️ G → H ⚖️
H
Loading...
⚖️Now You Know
Everything above this section is technical. This section is not. This section is about what changes for you now that you have read it.
If you are signing a deployment, approving a procurement, writing a compliance memo, signing off on a risk register, or allocating capital to an AI-enabled vertical, here is what is true on your side of the page.
Before today, you could argue you did not know. You could argue that the halting problem was an abstract result from computer science. That "deterministic compiled inference" sounded technical and you trusted the vendor. That cryptographic attestation was what industry called independence. That policy layers running on general-purpose hardware counted as governance. You could argue, in court, that the available technical guidance was genuinely unclear and that you acted in good faith on what was in front of you.
After today, that argument is weaker. The distinction between computational classes is not contested inside computability theory. The Notified-Body independence standard across regulatory regimes is not contested inside legal practice. The absence of an AI liability insurance market at the substrate signal level is not contested inside actuarial practice. Each of these is public, referenced, and traceable. Anyone doing their homework — including the opposing counsel in a future enforcement action — can establish that you had access to the argument.
This is not a threat. This is not a pressure tactic. It is the structure of fiduciary duty in the presence of accessible technical information. You are not neutral on what you sign once the information is available to you. The access itself shifts the standard against which your decision will be judged.
This is why we are publishing this argument openly, in plain English, with sources traceable to their primary form. The mechanism is under patent protection, but the argument is deliberately not proprietary. The market needs the argument to be common knowledge so that deployment decisions can be made on the right basis. The mechanism is what produces the measurement; the argument is what establishes that the measurement is needed.
The fiduciary question, compressed to one sentence: when your deployment is questioned — by a regulator, a carrier, a board member, or a plaintiff — will you be able to point to a measurable runtime signal that the AI was performing its authorized functional role, or will you be able to point only to policy documents and attestation signatures? The first answer survives. The second answer survives in proportion to how available the first answer was at the time of signing.
The fiduciary one-question test, the August 2026 Fiduciary Event Horizon, and the substrate independence comparison — the diagram you can hand to your board. (NotebookLM)
🪞🔬💡🧭🎯🧱⚙️⚖️ H → I 🗺️
I
Loading...
🗺️Where The Argument Lives
This post is a hub. The underlying argument has been developed across several companion pieces, each covering one orthogonal angle in depth. For readers who want to examine the full surface of the argument rather than take this summary on trust, the complete set is below.
Visual library.25 NotebookLM infographics — every argument in one image, organized by category (self-reference, regulatory, insurance/fiduciary, architecture, voice), each with full text transcription. If you want the argument at a glance, start there.
LinkedIn thread with the full technical exchange.The original post and its 80-plus comments walk the argument through every technical objection a credentialed audience produced over 72 hours. Russell Parrott (AI Accountability Library) on the legal text. Arnoud Engelfriet (author, The Annotated AI Act) on the regulatory lineage. Palle Simonsen (enterprise architecture) on deterministic inference. Dirk de Vos (QED Solutions) on cryptographic portability. Pascal Berchem (PEGL) on commitment-time governance. Meetesh Patel, Esq. on oversight-vs-audit distinction. Each challenger represents a category of objection the market will produce; each response is publicly on the record.
Patent. US Patent Application 19/637,714. 36 claims. Track One examination. Filed April 2, 2026. The filed mechanism is the architectural substance of this argument. The patent documents what a solution to runtime role continuity verification looks like under the computational-class test.
One diagnostic question, for every vendor claim you encounter: does the mechanism that is supposed to catch the problem run on a substrate that can execute arbitrary programs? If the answer is yes, the claim has the problem it was meant to solve. If the answer is no, the vendor must specify what computational class the mechanism runs in. That is the whole test.
🪞🔬💡🧭🎯🧱⚙️⚖️🗺️ I → tesseract.nu 🎯
The argument is not proprietary. The mechanism is. The measurement is what produces the signal. The signal is what lets you defend the deployment.
US 19/637,714 — 36 claims — Track One. Filed April 2, 2026.