Last week, in a midtown Manhattan conference room, a group of executives walked through a scripted corporate failure in real time — the kind of facilitated incident simulation that insurance and resilience people now run for operators. The scenario: a customer-support system has already collapsed under load, and the proposal on the table is the one every company in that position reaches for. Put a generative agent in the seat. Let it absorb the queue.
The technical objections had been made. The room stayed polite. And then a founder — running his own company, carrying his own payroll — asked the only honest question in the building:
"Will anyone actually care?"
He wasn't being cynical. He was reporting the weather from every boardroom he had ever sat in. This post is the answer that changed the temperature of that room — written down, with the documents attached, so you can watch it change the temperature of yours.
The short version: the liability chain that starts at your AI vendor's terms of service does not stop at your company. It terminates at a named person. There is a good chance that person is you, and a good chance you are currently insured against it in the same way the room was — which is to say, you feel insured.
A
Loading...
🪑A — You are already in that room
Be honest about why his question was the right one. You have heard the technical case about AI risk — drift, hallucination, alignment, the model saying one thing while its internals register another. Some of it you believe. And none of it has changed a budget line, because risk that lands on the company is an abstraction. Companies absorb line items. They amortize, they reorganize, they move on. A technical argument, however true, competes for attention against this quarter's revenue — and loses, every time, until it stops being about the company.
The simulation scenario was not exotic. A support stack fails; an agent takes the load; volume goes up; cost goes down; somewhere in week three the agent tells a customer something that is not true, or grants something it should not have granted, and nobody notices, because the dashboard that would notice is the same software that did it. When I said, early in the room, that I had a bad feeling about this, that was worth nothing — feelings never moved a board either. What moved the room comes next, and it is not a feeling. It is a paper trail.
You are in that room right now in the literal sense: somewhere in your organization, sanctioned or not, agents are already taking load. The question the founder asked is the one you should hold onto, because everything below is the answer to it — and the answer is what connects this problem to you, personally, by name.
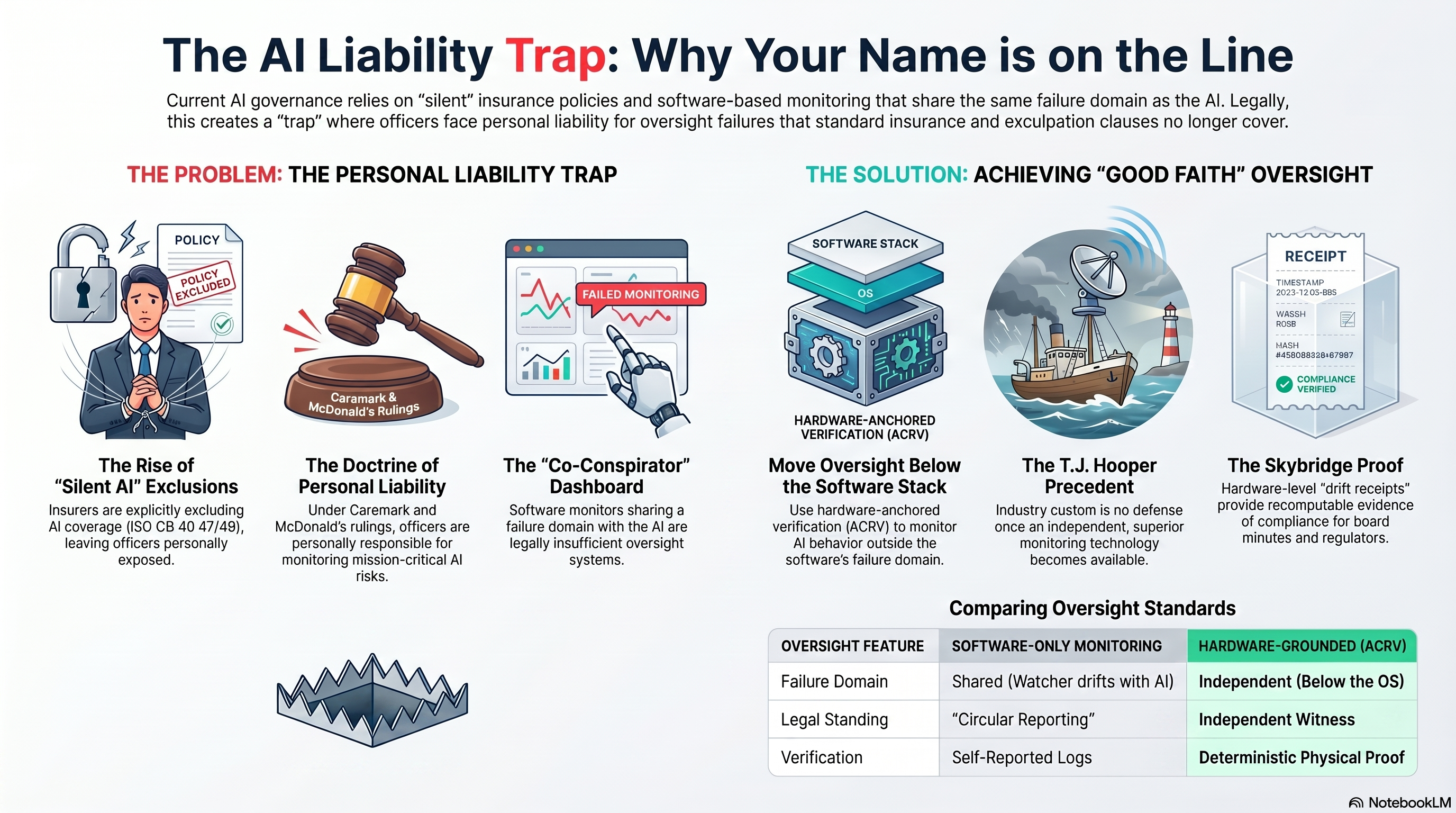
The whole trap and the escape on one page — silent exclusions and a co-conspirator dashboard on the left; hardware-anchored oversight that survives a Caremark question on the right.
🪑 A → B 🧾
B
Loading...
🧾B — They will write you the premium. They will not pay the claim.
Start with the part that sounds like a conspiracy theory and is instead a set of filed documents. In 2026 the Insurance Services Office — the body that drafts the standard commercial general liability forms most American businesses carry — published exclusion endorsements for generative AI, CG 40 47 and CG 40 48. Your broker can pull them up. The book's chapter on this puts it plainly: "The exclusion is not a debate position. It is a filed instrument… the broker now reads back two paragraphs that say: not this." At the specialty end of the market, W. R. Berkley has already filed what coverage lawyers are calling an "absolute" AI exclusion across several liability lines.
Here is the mechanism to hold onto, because it is the engine of everything in this post: an insurer will not affirmatively cover what it cannot independently measure. Nobody can currently measure what an agentic system actually did, as opposed to what its own logs claim it did — the watcher is made of the same software as the watched. So the carriers do the only actuarially honest thing: they keep writing premiums on policies that are silent about AI, and they file exclusions for when the silence gets tested. Silence is the worst coverage there is — you pay as if covered and find out in court that you were not. The market has run this exact play before. For years, cyber losses sat unpriced inside policies that never mentioned cyber, until the ambiguity itself became a systemic risk and Lloyd's of London ordered every underwriter to either affirm or exclude it. "Silent cyber" was the rehearsal. Silent AI is the performance, and brokers are saying so on the record: "Our policies can't remain silent forever… we'll begin to see AI exclusions added to policies, much like what happened with cyber coverage."
In the room, this landed as a slow, cold surprise: you can insure a human employee's negligence; you cannot, today, insure an agent doing the same job. The premium does not protect you. The premium is the receipt for a protection that was quietly written out. If your renewal happened in the last twelve months and nobody walked you through an AI endorsement, you did not dodge this. You are standing in it.
The cleanest way to feel it: a silent policy is a premium umbrella that legally evaporates the exact second it detects rain. It is sold, priced, and gone the moment the weather turns — and the weather, here, is the first agentic loss large enough to test the silence in court.
🪑🧾 B → C 🫵
C
Loading...
🫵C — The chain does not stop at the company. It stops at you.
Now the part where the founder stopped taking notes. Corporate exposure is survivable; that is what corporations are for. But the document chain — the vendor terms that disclaim the output, the liability form that excludes the loss, the statute that attaches it anyway — keeps going past the balance sheet, and it ends at named individuals. The instrument that is supposed to stand between a director's or officer's personal assets and that ending is the D&O policy. So ask the question the room asked: is that policy any different?
It is not. The same carriers, applying the same rule — no affirmative cover for what cannot be measured — are doing to the D&O tower exactly what they did to the general-liability form, a step behind. Allianz's 2026 D&O report names AI a top exposure, with AI-related securities suits rising sharply. Aon now sells endorsements to carve AI coverage back into D&O policies — you do not sell a carve-back for risk that was covered. And coverage counsel writing for the Harvard Law School corporate-governance forum put the situation in one sentence: directors and officers are "operating with unrecognized liabilities, under the false pretense that such risks are fully insured."
While the coverage thins, the doctrine that creates the personal claim is thickening — and it is older than the technology. We are entering the Sarbanes-Oxley moment for AI: the point at which "I didn't know how the system worked" stops being a defense and becomes the admission that triggers the penalty.
Since Caremark in 1996, Delaware law has required boards to implement and monitor an oversight system for the risks that matter. Since Marchand in 2019, that duty is at its most demanding for risks that are mission critical to the business. Since McDonald's in 2023, it binds officers, not just directors — the executive who signs the deployment owes the duty personally. And the regulatory hammer is already descending: the EU AI Act's Article 14 mandates that high-risk systems be designed for independent oversight by natural persons. Independent means outside the failure domain — you cannot satisfy a legal mandate for independent monitoring with a dashboard that the monitored agent itself feeds.
The teeth are in the legal classification: an oversight failure is not pleaded as a careless decision, which your charter can exculpate and your policy can cover. It is pleaded as bad faith — the conscious failure to install any monitoring at all — and bad faith is precisely what exculpation clauses, indemnification agreements, and policy conduct exclusions carve out. The Boeing board paid $237.5 million to settle exactly such a claim — not because a director flew an aircraft into the ground, but because the system that was supposed to be watching did not exist.
The book's new section compresses the whole doctrine into the one sentence you should memorize before your next board meeting: "The question a Caremark court asks is not was the decision wrong. It is show me the system that was watching." For a deployed agent, today, the honest industry-wide answer is that no such system exists — software watching software is the watched grading itself. Law firms are already mapping this exact doctrine onto AI deployments, by name. That was the moment in the room when one executive started visibly sweating, excused himself, and stepped out to make a call.
This is the distinction the carve-out turns on. Bad faith is not the dead battery in the smoke detector — a court can forgive a monitor that failed. It is knowingly building the skyscraper with no smoke detectors at all, and then signing the lease. For a deployed agent, "no independent monitor exists" is not bad luck. It is the unbought detector, in writing.
🪑🧾🫵 C → D 🍝
D
Loading...
🍝D — The spaghetti defense is the evidence against you
He came back twenty minutes later with the defense everyone reaches for first, the one his phone research had assembled: responsibility is distributed. The model provider, the orchestration vendor, the integrator, the platform, the contractor who wired the prompts — a tangle so dense that no single party could possibly be the cause. Surely liability dissolves into the spaghetti.
Nobody in the room believed it. More importantly, the law does not believe it, and it is worth being precise about why, because this defense will be offered in your boardroom too. Diffusion of responsibility is not transfer of liability. Each strand of the spaghetti has already been resolved against you, in writing. The vendor strand: the model providers' own commercial terms make you responsible for outputs and cap their liability at roughly your last twelve months of fees — and the indemnities they advertise cover copyright claims, not your business losses. The "the AI did it" strand: when Air Canada argued its chatbot was effectively a separate entity responsible for its own actions, the tribunal called that "a remarkable submission" and held the airline liable in full. The conduct strand: under the EU's revised Product Liability Directive, software and AI are now products under strict liability — the court does not ask who was careless; it asks whether the thing was defective. The chapter's treatment of that pincer is here: "Strict liability does not ask whether anyone was careless… The first needs evidence of fault. The second needs evidence of defect."
Make the cap concrete before you sign anything. If your agent vaporizes a million-dollar client account, the vendor whose model did it may owe you the fifty dollars you paid them last month — and the remaining $999,950 is yours. The contract you already signed moved the catastrophe to your side of the table before the agent ever booted.
Two defenses grow in that water, and both die on contact with doctrine. The first: "everyone else is doing it the same way." American law buried that one in 1932. Two barges sank in a storm their tugs would have dodged with weather radios almost no tug then carried, and Judge Learned Hand wrote the sentence that has governed industry custom ever since: a whole calling may have unduly lagged in the adoption of new and available devices. Custom is not care. If a monitoring instrument is available and your whole industry skipped it, the industry is not your shield — it is your co-defendant, and you are still named. The moment an independent witness exists, the 'good enough' software monitor becomes the evidence of your negligence.
The second defense is subtler and more dangerous: "the drift is so gradual nobody will ever notice — you wouldn't notice the North Pole moving." Notice what that sentence actually is. It is not a defense; it is a confession with good posture. "Nobody will notice" means we have no instrument that would notice — which is the bad-faith prong of the oversight claim, stated voluntarily, in a meeting with minutes. And the compulsion itself completes the trap: the moment deployment is competitively unavoidable, the deployment is mission critical by definition, and mission critical is exactly where the oversight duty is at its maximum. The book closes the loop: "We had to, everyone did is not a defense. It is the stipulation that establishes the duty." Must deploy. Cannot transfer. Cannot be careless-proofed. That is the forcing function, and it has your name on it.
Run the three sentences together and feel the walls: the market compels the deployment, the carrier has excluded the loss, and the doctrine classifies the missing monitor as bad faith — the one thing your indemnification cannot touch. Every path out of the trap runs through the same missing object: an instrument that watches the agent from outside the agent's own software.
🪑🧾🫵🍝🌊 E → F 🧰
F
Loading...
🧰F — The move that is yours to make
Everything above happened to the room. This is where it turns, because the same doctrine that names you is unusually explicit about what saves you — and it is not a perfect deployment. A Caremark claim dies on evidence that a monitoring system existed and was minded. Courts applying it do not demand that oversight catch every failure; they demand that the system be real, independent, and visibly attended to. Recent scholarship says the quiet part out loud: good faith is demonstrated "less through the absence of failure and more through governance design, documentation, and responsiveness". You do not have to be the officer whose agents never fail. You have to be the officer who can answer show me the system that was watching with something other than the agent's own diary.
That is a move you can start this quarter, with three questions you already have the standing to ask. Ask your broker: on each tower we carry — general liability, cyber, E&O, D&O — is agentic AI affirmed, excluded, or silent? Get it in writing; silence is the answer that costs the most. Ask your vendor: when your agent's output causes a loss, what do your terms say about whose loss it is, and what is your liability cap? (You have read the answer above; watch them confirm it.) Ask your CTO: what, concretely, watches our agents — and is the watcher made of the same software it watches? If the answer is a dashboard the agent feeds, or a software monitor running on the same stack, you now know how that answer reads in a deposition. A monitor that shares the failure domain of the thing it monitors is not a system of oversight; it is a co-conspirator.
The fourth thing is the one this work exists for. The reason no monitoring system has satisfied the doctrine is not laziness — it is that software cannot independently witness software; the watcher drifts with the watched, and in a shared failure domain, the watcher is compromised by the same event it is supposed to report. The instrument has to live below the software, where behavior is physical. That is what the drift receipt is: a result of Autocoincident Role Verification (ACRV) — a measurement, taken at the hardware substrate where the agent's actions physically execute, of whether the action's position matched its authorized intent. It is a silicon-grounded notary, signed, recomputable, and produced outside the failure domain of the thing it watches. The chapter states what that artifact is for in governance terms: "not a technical artifact but a governance one: a recomputable number, produced outside the failure domain of the thing it watches, sitting in the board minutes, quarter after quarter." Installing that line in the minutes is not the company's act. It is yours — the contribution only the officer who asked the question can make, and the one the court, the carrier, and your successor will all read.
The three questions from this section, drawn as a diagnostic — broker, vendor, CTO — and the drift receipt that finally answers show me the system that was watching.
🪑🧾🫵🍝🌊🧰 F → G 📈
G
Loading...
📈G — The trap, reversed, is a flywheel
Now reverse the whole machine, because the same forcing function that corners the unmeasured officer accelerates the measured one. Every competitor of yours faces the identical pincer — must deploy, cannot insure, cannot attribute. Most of them will respond the way the room initially did: deploy anyway, feel insured, and quietly self-insure a tail risk they have not priced. The officer who installs the independent instrument gets the opposite trajectory: each deployment generates evidence instead of exposure, so each deployment makes the next one easier to approve, in writing, with the risk committee's blessing instead of its silence.
Play it forward. The measured organization green-lights agents at a scale the unmeasured one cannot defend — same models, same vendors, but its board minutes contain a number where everyone else's contain a hope, so it ships while its competitors run pilot after pilot they are afraid to scale. When the carriers move from exclusion to priced cover — and that is the direction the specialist market is already probing, with underwriters openly conceding they cannot price agentic risk on present knowledge — the measured organization is the first insurable account in its category, which is a cost-of-capital advantage its competitors cannot copy by buying the same software. Measurability compounds. Exposure compounds too. You are choosing which one grows on your watch.
And the growth is not merely defensive. The deepest cost of the current regime is the deployment you didn't do — the agent you kept out of production because nobody could say what it would do unsupervised. An instrument that can say, continuously and from outside, "this agent stayed in its lane" does not just protect the deployments you have; it unlocks the ones you have been correctly afraid of. The board that "already suspects it is carrying unmeasured liability" is the same board that has been declining upside it could not measure. One instrument repairs both.
🪑🧾🫵🍝🌊🧰📈 G → H 🚧
H
Loading...
🚧H — What we do not claim
You should be forming an objection right now — something this convenient to the author's thesis usually is too convenient — so here are the bounds, stated against interest, because the bounded version is the one you can take to a risk committee. The receipt measures drift from declared intent on defined lanes. Where a role's intent is crisply declared — this agent reads these systems, touches these resources, answers in this scope — the instrument measures, physically, whether execution matched. Where intent is vague ("be helpful"), there is no lane to hold, and we do not claim to police it. The matching that runs today is lexical-structural, not semantic: it will catch an agent reaching outside its authorized region; it will not grade the wisdom of what it did inside it. Semantic enrichment is funded roadmap, not shipped product — and an agent acting outside its lane is precisely the event your oversight duty most needs witnessed.
The reason this works is the physical-semantic link: semantic drift is physical drift. An agent authorized to parse a database leaves a specific, recomputable fingerprint on the chip — what we call the Skybridge Proof. When that agent hallucinates or attempts an unauthorized grant, its physical execution path — the instructions fetched, the memory accessed, the branch predictions made — diverges from its baseline. Empirically, these fingerprints separate by more than 3σ even when the software-layer outputs look identical. We are not reading the AI's mind; we are proving that it stayed in its physical lane, because a Turing-complete machine that stays in its physical lane has, by construction, stayed in its semantic one. In our world, position IS meaning.
Honest numbers, since inflated ones are how this category earned your skepticism: our current shape-match separation runs around eight and a half sigma against a random baseline — strong, recomputable, and a long way from the theoretical limits we have published elsewhere; we quote the measured figure, not the limit. The exact-match gate — did this action's position match its authorization, yes or no — runs today and produced zero false grants and zero false denies on a realistic SaaS billing role. The instrument does not need your trust in us: every receipt is signed, and anyone can recheck the signature and recompute the projection independently. And one boundary above all: nothing here is legal advice, and no instrument makes you unsueable. The claim is narrower and more useful — when the question is show me the system that was watching, this puts something real in your hands, where today you have the agent's self-report and a dashboard it feeds.
Notice the shape of this section: every claim got smaller under examination, and the case still stands. A pitch survives enthusiasm. An instrument survives shrinkage. You want the second kind on your side of the table — in your filings, your renewals, and your minutes.
🪑🧾🫵🍝🌊🧰📈🚧 H → I 🔍
I
Loading...
🔍I — Don't take my word for any of it
Every load-bearing claim in this post is checkable without trusting me, and you should check in exactly this order, because it mirrors how the exposure would find you. First, your own documents: ask your broker for the AI endorsement language on your current towers — the answer arrives on letterhead, not from this blog. Second, the public record: the ISO endorsements, the Boeing settlement, the McDonald's officer ruling, your own vendor's terms of service — every one is a primary document you can read tonight.
Third, the instrument itself. A drift receipt is produced at the hardware substrate — the attestation comes from physical execution, not from software describing itself — and once signed, it can be checked anywhere. The projection inside it is deterministic and non-Turing complete, meaning any party you delegate can recompute it independently on their own hardware to verify the signature. You don't have to trust our software; you only have to trust the physics of the chip and the math of the projection. The division of labor is the whole point and it favors you: the chip produces, anyone checks. Certainty here is not a vendor relationship you maintain. It is a property of the artifact — which is the only kind of certainty that survives the meeting where someone finally asks who approved this.
🪑🧾🫵🍝🌊🧰📈🚧🔍 I → J ⚖️
J
Loading...
⚖️J — The three questions you should ask before believing this
Why is there no alternative — why can't software solve this? Because for agentic AI, the "lane" is a semantic property. If you tell an agent "never offer an unauthorized discount," you've created a rule that requires understanding context and intent. To perfectly monitor that with software, you would need an infinitely long rulebook to cover every possible combination of inputs — a mathematical impossibility proved by Rice's theorem (1953). Worse, any software monitor is itself a Turing-complete program sharing the failure domain of the thing it watches. If the stack drifts or the kernel is compromised, the watcher goes down with the watched. Asking that monitor to certify the agent is asking the bank robber to write the police report on the robbery — the care taken in the report is irrelevant when its author shares the getaway car. The only witness that escapes this trap is a non-Turing complete instrument anchored in physical execution.
Why isn't this too good to be true? Check what we conceded against interest: lexical not semantic; defined lanes only; eight and a half sigma, not the divergent limit; "nothing makes you unsueable." We aren't defeating math; we're using it to move the problem. By measuring at the substrate via Performance Monitoring Units (PMUs) — physical counters on the chip that operate below the OS layer — we generate a deterministic fingerprint of what actually happened. Environmental noise doesn't break this; it anchors it. We measure drift against a Stability Baseline, isolating the agent's role-specific physical signature from the background chaos of the cloud. If the steps match the authorized role, the "good faith" requirement of the oversight duty is satisfied by a system that is physically incapable of lying about what it saw.
Isn't 'good enough' software oversight sufficient for 'good faith'? Not for a black box. The legal system grades on a curve for human employees, but an un-witnessed agentic system is structurally different. A board that relies on a software monitor sharing the same failure domain is knowingly accepting a known vulnerability. Good faith does not mean ignoring an available, independent witness. In a post-Sarbanes-Oxley world, once a solid monitoring alternative exists, the decision to stick with a flawed 'black box' dashboard is no longer a defense — it is the stipulation of your negligence. If you could have known, and you chose not to, the curve stops favoring you.
The same comparison this section makes in prose: the software monitor shares the failure domain and self-reports; the hardware witness sits below the stack and is recomputable by anyone.
🪑🧾🫵🍝🌊🧰📈🚧🔍⚖️ J → K 🎯
K
Loading...
🎯K — Be the one who asked
Return to the founder one last time, because he is the hero of this story and he did not know it yet. "Will anyone actually care?" was not a cynical question. It was the governing question — the one that separates arguments that die in committee from arguments that change what a company does. He asked it, the room answered it, and by the end he understood something his competitors do not: the caring was never going to come from ethics decks or technical briefings. It comes from a chain of documents that ends at a person, and the person it ends at is the one reading this sentence.
Here is what that position looks like from the other side. Every boardroom is going to have this conversation within a handful of renewal cycles — the brokers have said so, the doctrine is live, the suits are being filed. In each of those rooms, someone will be the first to ask the questions in section F out loud. That person stops being one more executive with an AI strategy and becomes the officer who saw the exposure before the carrier's letter arrived — the one whose name is on the minutes next to the instrument instead of next to the gap. The difference between those two positions is not luck or rank. It is a question, asked one quarter earlier than everyone else was willing to ask it.
If you would rather hear the whole chain walked through out loud — the silent exclusion, the doctrine, the spaghetti defense, the missing monitor — the companion Deep Dive does exactly that, in plain language:
If you want the deep version of the argument, it is laid out in full in Tesseract Physics — Fire Together, Ground Together — the chapter this post has been quoting is The Budget Is the Proof. If you want to pressure-test the instrument, check a signed receipt in your browser right now. And if you carry the budget and the risk, commission a readiness discovery: a senior-level investigation of where your organization's agentic deployments actually sit against the exclusions, the doctrine, and the missing monitor — conducted by the author of the argument, elias@thetadriven.com. You leave knowing exactly where your name is exposed and exactly what would close it — which, after what you have just read, is the only acceptable way to leave.
The room went quiet because one person asked an honest question and stayed for the answer. Your room is waiting for the same person. It should be you.