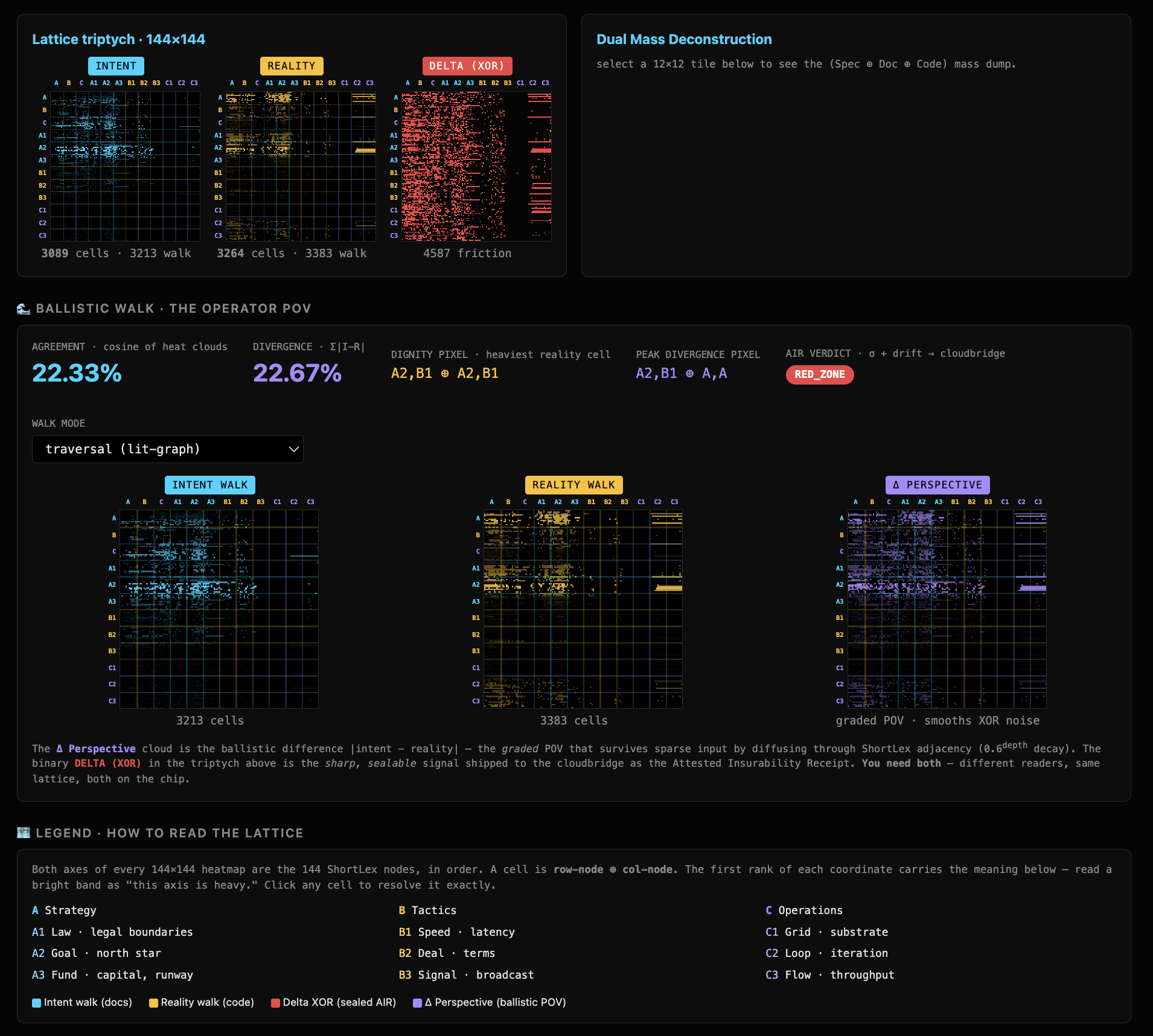
You want to deploy AI that acts on your behalf, and you keep hitting the same wall: when something in the system shifts, no monitor can tell you where it shifted. They tell you that something changed — a log lit up, a metric moved — and then point everywhere at once. That is not a measurement. It is an alarm. Last night we built the instrument that points at the address, broke it on purpose four different ways to find the one that works, and measured exactly how unlikely it is that the answer is luck. This is the full account, every number, written so you can decide for yourself whether to believe it.
The substrate: 144 semantic zones, fixed. Every figure below is a reading against this lattice — and the one that matters to you is the reading that found a single bright zone where every other reading handed you a smear.
A
Loading...
🧠A — The brain surgeon and the locked goal
the planted edit · sigma as luck-odds · alarm vs instrument
One planted edit, one known address, 144 zones to choose from — that is the whole test, and it is answerable because we buried the answer ourselves before asking. Pass it, and you stop getting alarms and start getting addresses.
Picture a one-page document about brain surgery. Now make a single, clean, drastic edit: every instance of the phrase brain surgery becomes plumbing. Same length, same shape, same grammar — but the meaning of one region of the text has been gutted and replaced. A human reading both versions side by side would point at the change instantly. The question we locked ourselves to last night was whether the instrument could.
Not "did the document change" — every diff tool on earth answers that. The harder question, the one that decides whether any of this is real: which of the 144 semantic zones did this edit touch, and how unlikely is it that the instrument landed on the right zone by chance? We measure that unlikeliness in sigma, the instrument's own significance bands: under 1 is chance, 1 to 3 is weak, 3 to 6 is localized, 6 and above is outstanding.
We planted the probe document at a known coordinate, made the brain-surgery-to-plumbing edit, and asked the instrument to find the address — an address on a map whose 144 zones are themselves held in place by a recursive walk of their own definers, which section D unpacks. The book frames why this is the whole ballgame for a grounding gate: a helm that steers identity is worthless if it cannot feel where a change landed. As chapter 8 puts it, the small helm has to feel the edit. A gate that grounds identity is worthless if it cannot tell you where a change landed.
What is in it for you: the difference between an alarm and an instrument. An alarm says "something is wrong." An instrument says "it is here, and here is how sure I am." If you are accountable for an AI system, the second sentence is the only one worth anything — it is the difference between a 3am page that sends ten engineers searching everywhere, and one that hands them an address.
🧠 A → B ⚖️
B
Loading...
⚖️B — The two sigmas, both ways
two sigmas · opposite grading · low sigma as honesty
There are two sigmas in this work — confidence on your real commits, and response to a planted edit — and they grade in opposite directions. Holding them apart is what protects you from misreading an honest "not sure yet" as failure, or a loud number as proof.
Here is the shape of the fix, up front, so you know what the numbers below are measuring: an ordinary compressor pointed at a fixed 144-zone map, reading the zone where meaning stops compressing the same. Sections C and D earn that sentence in public — four lenses fight for the job and three lose. But before any of those numbers land, you have to know there are two different sigmas in this work, because conflating them is the most common way to misread everything below; skip this ruler and the numbers read backwards.
The first is sigma-drift: instrument confidence on a real commit. When you point the instrument at an actual change someone made to a real document, sigma-drift tells you how much to trust the picture it draws. And here is the part that trips people: a low sigma-drift is not a verdict that the work was bad. It means the instrument cannot yet trust its own picture of where the change landed. The bands read as honesty about confidence: 0 to 3 is "I can't trust this picture yet," 3 to 6 is "a shape is forming," 6 and up is "now I'd stake a claim on it." Low sigma is the instrument refusing to lie to you about how sure it is.
The second is sigma-response: sensitivity to a sized intervention. This is the test from section A — we deliberately inject a known edit of known size and ask whether the instrument feels it at the right address. Here, high and localized is the win: it means the instrument is sensitive enough to register a real perturbation and precise enough to put it at the correct coordinate. A high sigma-response is the instrument proving it has working nerves.
Read it this way and the whole night clicks: sigma-response is how we proved the instrument can feel an edit at the right address (the brain-surgery probe). sigma-drift is what that same instrument reports when you turn it loose on your real, messy commits — and a low number there is a feature, not a failure. The instrument that admits "I'm not sure yet" is the only one you can trust when it finally says "I'm sure."
🧠⚖️ B → C 🎯
C
Loading...
🎯C — The lens tournament: three honest losers
the tournament · three losses, printed · refutation as receipt
Three of the four lenses we ran at the edit lost, and their losing numbers are printed below. That is exactly why the winner is believable: it survived a public tournament, not a showcase.
We did not pick a favorite instrument and hope. We ran four different lenses at the same edit and let them fight, and we published every loss, because a refutation hidden from you now is a refutation you pay for later, in production, on your budget. Three of the four lost — and they lost honestly, which is its own kind of result you get to keep.
Lens one: mass. The obvious move — take the whole-document difference field, see where the change piled up. It smeared. The mass spread across 110 of the 144 twelve-by-twelve blocks and ranked the true zone 38th of 144 — a sigma of 0.61, squarely in chance. The edit was real and drastic, and the mass simply could not find it. This is the lesson the book has been making for chapters: the obvious quantity is the wrong quantity. As it argues, the obvious thing to measure is the thing that smears.
Lens two: rank-per-tile. Ask each tile to vote its own position. Better in spirit, but it gave sigma 1.27 — still weak. A uniform random draw could have matched it. Refuted.
Lens three: claim attribution. Sense only the claims that actually changed between the two versions, not the whole document. This one aimed: the target zone climbed from 38th to 2nd, and the localized sigma jumped into the low fives. Directional, real, useful — but a second lens, never the verdict on its own. It points; it does not prove.
Why this matters to you: a vendor who shows you only the lens that worked is selling you a story. The three losers above are the receipt that the winner below was not cherry-picked. The refutations are the feature. An instrument that has never been shown to fail has never been tested.
🧠⚖️🎯 C → D 🗜️
D
Loading...
🗜️D — The compression witness wins
gzip as meaning detector · one bright address at 8.85 · the walk under the map · prior art, named
The winner is gzip, of all things: one bright address at 8.85 sigma where mass saw a smear across 110 blocks. The principle is peer-reviewed — Cilibrasi and Vitányi's clustering by compression — we only aimed it, and it turned "something moved" into a coordinate.
Then the fourth lens won, and it won with a tool nobody in this field reaches for: gzip. The idea is older than the field's anxiety about it. Two strings that share structure compress together better than they compress apart — the savings is the shared meaning. So we took both sides of the edit, assigned every claim to its nearest of the 144 anchors, and compressed the claims that land in each zone. Where the edit touched, the two sides' compressed lengths diverge. Where it did not, identical strings compress identically and the reading is exactly zero.
On the living yardstick, the champion read sigma 8.85 — outstanding — with the target zone ranked 2nd and only a handful of zones nonzero at all. One edit read 19.01. Where mass saw a smear across 110 blocks, the compression witness saw a single bright address. The book lands it in plain terms: the mass could see nothing; the compression witness saw a single bright address.
This is Cilibrasi and Vitányi's clustering-by-compression — a published, peer-reviewed technique for measuring similarity by how well two things compress together — pointed inward at our own substrate and aimed at one question: where did the edit land. We did not invent the principle. We aimed it.
One more piece, because it answers the oldest objection waiting underneath everything above: a dictionary defines words with other words, forever — so what holds the 144 zones themselves in place? A recursive walk on the lattice does. Start at a zone's row, follow only its significant columns, jump to each column's transposed row, and recurse — ply by ply, each ply's contribution decaying — so every zone is pinned by the chain of its definers, and its definers' definers, made finite and physical instead of regressive. That walk is the instrument's other half: the walk grounds the map; the witness reads the sense. Compose the two and a drift reading stops being a delta and becomes an address — not "the meaning moved" but "the meaning moved here, on a coordinate system that is itself held in place." Honest bounds, as always: the walk is measured per-commit in the five-to-ten-million-walks-per-second range and chains to ply 7 in the commit-time readouts; the localization lenses in this post read the sense alone — the walk holds the ground under them, it did not aim them.
The plain-English version: if you zip two files and they squash down small together, they share a lot. If they barely squash at all, they are strangers. We zip the meaning of each zone before and after an edit; the zone where the zip suddenly gets worse is the zone the edit hit. No embeddings, no model in the loop, no training. A 50-year-old compression algorithm, used as a meaning detector.
🧠⚖️🎯🗜️ D → E 🔭
E
Loading...
🔭E — Step back: the size of what just happened
against the field's prior · the adversarial reader · why believe it · what it unlocks
A 64-bit hash and gzip just localized an edit at the level of meaning — the thing a theorem proves no software can decide — with odds-of-luck carrying thirteen zeros. If you slow down for one section, make it this one: it is the one where your own prior gets to fight back.
Before the bookkeeping — the controls, the yardstick, the estimator, the outside witness, the panel — one section to say plainly what you are looking at, because the numbers above are easy to walk past one at a time, and walking past them costs you the thing they hand you.
How unexpected this is. Your prior here is the field's prior, and it is settled doctrine: semantic tasks need embeddings, attention, billions of parameters. Meaning is supposed to live in high-dimensional vector spaces that only a trained model can navigate. What localized a meaning-level edit above was a 64-bit lexical hash and gzip — arguably the two most unglamorous tools in computing — landing it at one address in 144, with 19.01 sigma of target dominance on the strongest edit while the controls sat at exactly zero. Propose that on paper and you would laugh it out of the room yourself. Which is exactly why it was registered as a prediction before the run — so that when the run paid it, the thing overturned was your prior, on the record, and not our enthusiasm after the fact.
So you do not have to take our framing of your seat on faith, we ran this post past an adversarial reader before publishing — an AI instructed to role-play you: the person who signs the check, a skeptic who could be won but did not have to be. Hitting the gzip reveal, it wrote: "They are using... a 64-bit lexical hash and gzip? Gzip? The entire field is trying to build a smarter brain to watch the first brain, which just creates an infinite loop of hallucinations. These guys stepped outside the loop." And at the close: "They aren't claiming they defeated Rice's Theorem; they are admitting the theorem holds, but proving that it doesn't matter, because the physical footprints give you everything you need for governance." That is a synthetic stand-in for your chair, not you — every number it reacted to is above, so you can run the same audit yourself and see whether your monologue diverges.
Why you should believe it. Not because we say so. Because the predictions were registered before the runs and the refutations were published next to the wins: rank-per-tile died in public, and so did our own pet theory of how the response should scale. And because of five checks, each of which gets its own section below: the controls read exactly zero, every run; the yardstick regenerates from the live seeds on every reading, so there is nothing for the instrument to memorize; the estimator fails conservative — every residual bias deflates the claim; the same instrument performed on a real committed paragraph it had never seen; and the claim holds across twelve independent edits, not one. The runs reproduce bit-exact. If a clause here sounds like an assertion, its receipt is a few sections down.
What it hands you. Semantic events in your system acquire addresses. Your edits become auditable at chip speed, because the witness is a hash and a compressor, not a model call you have to budget for. Drift stops being a feeling you have to defend in a meeting and becomes a receipt with a coordinate and a magnitude — and a receipt with a coordinate and a magnitude is something your underwriter can price, which is your door to insurable AI behavior. The law scales by construction: the same family discipline that built 144 zones builds 20,736, because the lattice is the square of its own anchor list. And the deepest consequence is the shortest to say: reach is verify. If the instrument can reach the address, it has already verified what lives there.
How insane it is that you get to use this. Rice proved you cannot decide what code means — not "it is hard": cannot, ever, with any model of any size. And yet meaning casts a compressible shadow, and the shadow lands at the right address nine times in twelve — section J walks the whole hand — composing to a joint probability with thirteen zeros in front of it. The undecidable thing left footprints. No software will ever decide what your program means; you, with gzip, can now watch where its meaning moved.
If the sections on either side of this one feel like careful bookkeeping, this is what is being booked: meaning — the thing a theorem says no software can decide — leaves a measurable, addressable, reproducible footprint that a 50-year-old compressor can read. You do not have to take the big framing on faith. Every claim in it has a number in this post and a control at zero beside it.
🧠⚖️🎯🗜️🔭 E → F 🧪
F
Loading...
🧪F — Nothing in nothing: the controls at zero
When nothing happened, the instrument read exactly zero — every lens, every run, as a property of the math rather than a tuning choice. This is the cheap-looking number that makes every expensive-looking number in this post mean something.
A high number means nothing if the instrument also finds signal where there is none. So the first thing we check, every single run, is a no-op: compare a document against an identical copy of itself. On every lens, on every run, the control reads exactly zero. Not "small." Not "0.03 within noise." Zero.
For you, the buyer of trust: the control is the cheapest thing in the world to fake and the most expensive thing to fake honestly. Anyone can show you a big number. Ask them what their instrument reads when nothing happened. If the answer is not a hard zero, the big number is decoration.
🧠⚖️🎯🗜️🔭🧪 F → G 📏
G
Loading...
📏G — The living yardstick: staleness made impossible
The yardstick rebuilds itself from the live seed library on every reading, so it cannot quietly go stale — and when we fed it a stale pair anyway, it read negative rather than pretending. Most dashboards rot green; this one confesses.
Here is the failure mode that quietly ruins most measurement systems: the test goes stale. You build a benchmark, the system evolves underneath it, and the benchmark keeps reporting on a world that no longer exists. So we made staleness impossible by construction. The test pair is keyed to the hash of the seed library that generated it. Change a single seed and a brand-new test is minted automatically. There is no old test to drift away from, because the test is regenerated from the current seeds every time.
We know this works because we watched the disease announce itself. When we read a stale pair — one generated against a seed library it no longer matched — it returned minus 1.26. A measurement that can read negative when it should read nothing is a measurement that is telling you the truth about its own staleness. The living yardstick reads zero on a no-op and negative on a mismatch; both are the instrument refusing to pretend.
The translation: most dashboards lie slowly. They show green long after the thing they measure has rotted, because the yardstick froze in place. This one cannot, because it is rebuilt from the live thing it measures on every reading. When it goes stale, it does not show green — it goes negative and tells you.
🧠⚖️🎯🗜️🔭🧪📏 G → H ⚙️
H
Loading...
⚙️H — The estimator fails conservative, on purpose
We found a bug that flattered us — clean bullseyes reading as misses — fixed it, and left every remaining bias pointed against ourselves. The numbers in this post are floors, not ceilings.
There was a subtle bug in our own favor that we refused to keep. When an edit lands in a single zone so cleanly that the surrounding population has almost no variance, a naive statistical reading collapses to zero — the instrument calling its own bullseye a miss, because there was nothing around it to compare against. We closed that gap: a surgical, single-zone hit now reads its exact placement significance, and the median across the panel rose from 0 to 2.46.
This is the opposite of how most metrics are tuned. The incentive everywhere is to round up — to let the number flatter the builder. A fails-conservative estimator does the unfashionable thing: when in doubt, it reports less confidence than it has. The numbers you see are floors, not ceilings.
🧠⚖️🎯🗜️🔭🧪📏⚙️ H → I 🔓
I
Loading...
🔓I — Breaking the circularity with an outside witness
Aimed at a real committed paragraph its seed library had never seen, the same instrument still localized at 4.33 sigma. The grading-its-own-homework objection dies here by measurement, not by argument.
There is one objection left, and it is the sharp one. Our synthetic test pair is derived from the seed library — so a self-consistent piece of junk could still "localize" to its own junk anchor and post a big number that proves nothing. If the test grades its own homework, the grade is meaningless.
So we ran the exact same instrument on a real, committed repository paragraph — prose the seed library had never seen, written by a human for an entirely different purpose. The compression witness read sigma 4.33. Localized, on text from outside its own loop. The circularity is not waved away with an argument; it is broken with a measurement on independent material.
What this buys you: the instrument is not graded on a curve it drew itself. It performs on text it has never met. That is the line between a demo that works only on the maker's own examples and an instrument that works on yours.
🧠⚖️🎯🗜️🔭🧪📏⚙️🔓 I → J 📊
J
Loading...
📊J — From one bright address to the whole hand
twelve edits, one distribution · which numbers lead · the family law of seeds · a prediction, paid
Twelve independent edits; nine landed their target in the top three of 144; jointly that is 7.29 sigma against a uniform null, read conservatively. One bright address is an anecdote — a distribution is an instrument.
A single bright address is an anecdote. The claim is a distribution. So we swept twelve independent edits and asked the panel-level question: across the whole hand, how unlikely is it that the instrument keeps landing in the top three of 144? Nine of the twelve edits moved their target and ranked it third or better; the worst surviving hit sat at rank three of 144. The joint, conservative reading — a binomial against a uniform null — is sigma 7.29. Not one lucky address. A hand that keeps finding the right address.
Three numbers that sound alike and aren't. The 19.01, the nine-of-twelve, and the 7.29 measure three different things, and the objection that pits them against each other — how is the instrument nineteen sigma if a quarter of the map stays silent? — dissolves the moment they are held apart. Per-reading strength (the 19.01) is how decisively the instrument speaks when it speaks: the loudness of one verdict, never a success rate. Map coverage (the nine of twelve) is how much of the map can speak yet — and it is deterministic per tile, not a coin flip: at a given seed-library state the same tile always hits or always misses, every miss is a named address with weak seeds and a diagnosed cause, and a single change to the family law moved coverage from four to nine. The joint claim (the 7.29) is the panel-level verdict that the speaking is not chance: the probability that nine of twelve land top-three of 144 by luck is about 1.5×10⁻¹³. The honest sentence that holds all three: strength is how loudly it speaks, coverage is how much of the map can speak yet, and the joint number says the speaking is not luck — with coverage the number still climbing, each miss carrying its diagnosis.
What leads these results, honestly. The loud numbers and the true ones come from different lenses, and you should know which is which before you repeat either. Compression magnitude makes the per-tile spectacle — the 19.01 — but rank across the panel makes the claim; the spectacle is volume, the ranking is truth, and mass never led anything, anywhere. Grade matters too: the sweep runs bench-grade — regenerated document pairs, bit-for-bit repeatable, never touching a repository file — while the brain-surgeon pair was demo-grade, a real file across two real commits. Both are measured; they answer different questions, and we say which numbers came from which. One confession with its fix attached: for a while, the self-improving loop's own quality gate optimized a correlated proxy instead of the thing we actually wanted. It now gates primarily on the target leading the ranking, and any regression there refuses outright.
And underneath the panel sits the rule that made it possible: a family law for how the seed corpus is built — children are the unique atoms mined from the whole repository, parents are honest summaries of their children, and siblings are pulled toward orthogonality so they do not blur into each other. Tightening that law halved the misses from seven to three and doubled the number of outstanding readings. The physics even named the lever in advance: the correlation between an edit's measured response and the orthogonality of its neighboring zones came in at −0.91, a registered prediction that the redistribution then confirmed. The instrument got better because the ground got better — exactly the book's inversion: constrain the substrate; free the agent. The compression witness is what the freed agent uses to check that the floor is still where it left it.
The distribution is the difference between "I once found the right zone" and "I find the right zone nine times out of twelve, and here is the probability that is luck: about one in ten trillion." One is a story. The other is an instrument you can put in a pipeline.
🧠⚖️🎯🗜️🔭🧪📏⚙️🔓📊 J → K 🧾
K
Loading...
🧾K — The evidence: three questions, answered
the forced move · the honest weaknesses · the empty seam
Three questions any careful reader owes themselves — why is this forced, why is it not too good to be true, why has nobody else done it — answered with sources, and with our weaknesses printed first. The audit is the pitch.
Before any ask, the three questions a careful reader is right to demand. (If you arrived here from the drift you can't see, this is the instrument that closes the gap that post named.)
Why is there no alternative — why is this a forced move, not a preference? Because of a 1936 result with a 1953 generalization. Rice's theorem proves that every non-trivial semantic property of a program is undecidable — no piece of software can, in general, verify what another piece of software means or does. That is not an engineering gap that a better model closes; it is a wall. The only way past a wall is to stop asking software to certify software's meaning and instead anchor the one property you can check — is the thing doing the task still the thing that was authorized — to something physical. As the book argues across why drift is not a bug, the record has to be the event. Hardware can attest which bits ran. It cannot attest what they meant — and neither can any other software, which is precisely why a measurement of drift, with a hard control and an outside witness, is the move that remains.
Why is this not too good to be true? Because we have spent ten sections telling you where it is weak. The headline honest band is roughly 8.5 sigma, not the 600 you may have seen quoted elsewhere — that 600 is a theoretical limit as a correlation goes to zero, a limit we have never measured and do not claim. The controls read zero. Three of four lenses were refuted in public. The estimator is tuned to under-report. The instrument reads negative when it goes stale. And two honest boundaries stay loud: this is lexical, not semantic — we measured that boundary rather than hedge it: in a pre-registered paraphrase probe a synonym swap moved the signature as much as a foreign-domain swap (median ratio 0.94 over eight tiles), so the instrument senses reuse of form and is semantic only to the degree the seed curation compiled meaning into form — and bench time is not chip time; the millisecond figures are the on-silicon target, not the benchmark harness you would clock today. An instrument that tells you its own limits this precisely is not selling you a miracle. It is showing you the audit.
Why has nobody else done this? Because it sits on an unfashionable seam between disciplines that do not talk: Kolmogorov complexity — Li and Vitányi's textbook is the canon — and Cilibrasi and Vitányi's 2005 normalized compression distance on one side; Charikar's 2002 SimHash and the locality-sensitive-hashing world on another; Harnad's 1990 symbol grounding problem and Rice's 1953 undecidability on a third. The field's energy is in larger models; the answer to a problem larger models cannot solve was always going to come from the corner nobody was looking in — compression as a meaning detector, aimed at a fixed geometric substrate. No triumph in that. Just the seam being quiet enough to work in.
If you are accountable for an AI system: the question that decides your exposure is not "is the model good." It is "when it drifts, will anyone be able to point at where — and prove it was not luck." Last night that question got an answer with a number attached, a control at zero, and its own weaknesses printed beside it.
🧠⚖️🎯🗜️🔭🧪📏⚙️🔓📊🧾 K → L 🚢
L
Loading...
🚢L — What you can do with an instrument that points
the night in one breath · alarm to address · the gap you can close now
Everything above compresses to one move you can make now: close the where-did-it-drift gap with a measurement that has a control at zero and an outside witness — no retraining, no license. Closing it before it bites is the cheap version.
Here is the whole thing in one breath. We set the hardest test an alignment instrument can face — change one thing in one place, point at the address — and we let four lenses fight for it in public. Mass smeared. Rank-per-tile was weak. Claim-attribution aimed. And a 50-year-old compression algorithm, pointed at a fixed substrate, found the one bright address at 8.85 sigma, held a hand of nine-in-twelve at 7.29 sigma across the panel, read exactly zero when nothing happened, read negative when it went stale, and performed on a paragraph it had never seen.
For you, that is the move from alarm to instrument. From "something in the agent shifted" to "it shifted here, and the odds this is noise are about one in ten trillion." From a monitor that points everywhere to a witness that points at one coordinate. The book frames the why beneath it all in the small helm — the tiny grounded thing that steers the vast ungrounded one — and the compression witness is how that helm finally feels the wheel.
Here is what you now know. The instrument speaks decisively where its map is seeded — when it speaks, it speaks at up to nineteen sigma with a control that reads exactly zero. The map's coverage is climbing with named causes — nine tiles of twelve can speak today, and every silent tile carries its diagnosis and its fix. And the joint claim is not luck: at about one in ten trillion, the verdicts compose into an instrument, not an anecdote.
If you own a deployment and you cannot today say where your AI drifts when it drifts, that is the gap to close, and it is closable now — no model retraining, no license, just a measurement with a control and an outside witness. Read the full argument in Tesseract Physics, and if the gap is keeping you up, that is the conversation worth having.