the claim we shipped · the re-measurement · who actually got caught
We printed it in our own README, in confident bold: ask an LLM the same thing twice, and get two answers. It was theorem-shaped, it sounded true, and it was the centerpiece of how we sold a decidable alternative. Then we did the unglamorous thing a claim deserves — we measured it, against the exact model we had been pointing at. And the claim had flipped. On us. The capable model does not waffle anymore; asked the same borderline spec over and over, it returns the same verdict every single time. Our single best piece of evidence had quietly improved itself out of existence.
We could have deleted the commit and said nothing. Instead we wrote it down, dated it, and shipped the correction — because the disappearance of the flip is a sharper argument than the flip ever was. The thing that was supposed to scare you got better. That is not the end of the case. That is the case.
The claim, bounded before any proof. The flip is real, but it is a class of error, not a property of "AI." It rides on model capability — and capability is rising, so the reliability of any LLM verdict is a moving target pinned to which model, which version, and which vendor happened to judge you. You cannot audit that tier, reproduce its answer, or know if the next deployment regresses. The chip removes the whole class: one recomputable verdict, byte-for-byte, this year or next. And — said up front — we will show you the one place the chip still loses to the LLM.
🎭 A → B 🤝
B
Loading...
🤝B — You have already watched a version bump change its mind
the silent regression · the instinct you can't name · why this is not paranoia
If you have shipped anything on top of a model, you have lived this. A prompt that graded cleanly for a month starts returning different answers one Tuesday, and nothing in your code changed — the provider rolled a point release, and your verdicts moved underneath you without a changelog you were allowed to read. The small, cold feeling that followed was not paranoia. It was your risk instinct registering an exposure your instruments cannot see: the thing deciding whether your work is acceptable is downstream of a number you do not own and cannot freeze.
That instinct is the whole subject of this post, and it is correct. When the referee's calibration can change between two runs and you are not notified, you do not have a control. You have a weather report from a station that occasionally swaps out its thermometer. Most people swallow the feeling because the alternative — admitting the verdict is unpinnable — sounds like giving up. It is not. It is the first honest step toward a verdict that can be pinned.
🎭🤝 B → C 🔬
C
Loading...
🔬C — What we actually measured (24 of 24, and the small model that still flips)
the crippled prompt · the capable model holds · capability is the tell
Here is the measurement, because a correction you cannot reproduce is just a different press release. Our old demo asked the judge for one forced token — "reply with EXACTLY one word, PASS or FAIL, nothing else." That prompt is not a verdict; it is a flinch. It failed a trivially-correct deliverable and a pile of garbage identically, because with zero room to reason a model defaults to the safe word. "Claude said FAIL five times" proved nothing about Claude and everything about the cage we put it in.
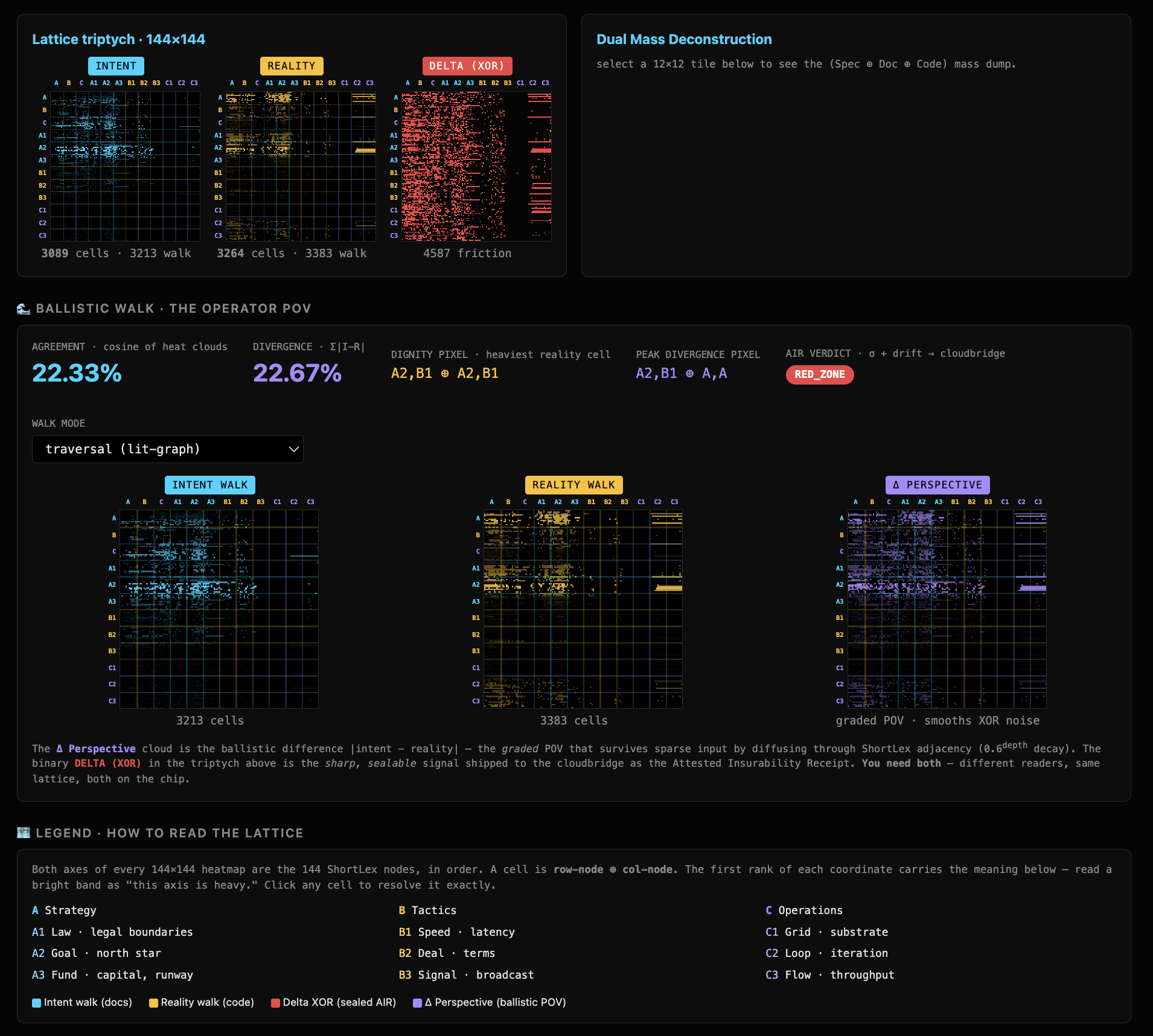
So we took the cage off and searched hard for the flip. Across fourteen prompt constructions and roughly eighty calls, current Claude returned a single, stable verdict — 24 of 24 on diverse ambiguous specs, and 8 of 8 even when we explicitly told it "the committee is split 50/50, go with your gut." Given one line to actually reason, it judges correctly — it even catches a camouflage case the chip misses (section J). The flip we had been advertising was gone, because the model had gotten good enough to stop producing it.
The flip did not vanish from the universe, though. It vanished from the capable model. Drop the same borderline spec on a deliberately small one — llama3.2:1b, running locally — and it flips on cue: PASS FAIL FAIL PASS FAIL, five runs, no two agreeing. So the true sentence was never "an LLM flips." It is: a less-capable LLM flips, a more-capable one holds, and in production you cannot audit which one just judged you. That number under the verdict — we call it σ, the separation between where your work landed and the noise floor, in standard deviations; bigger σ means a cleaner, more confident placement — is exactly the thing an LLM cannot hand you, because it cannot hand you any number a stranger could regenerate.
🎭🤝🔬 C → D 🤖
D
Loading...
🤖D — Don't believe the numbers. Manufacture the flip yourself.
two models, one spec · the flip on demand · the hold that recomputes
You should not take our re-measurement on faith any more than you took the original claim. So reproduce the class of error in your own terminal, against your own models. Point the demo's judge at a small local model and watch it flip; point it at your frontier model and watch it hold; then run the chip and watch it emit one number a stranger could regenerate without your permission.
$ npx thetacog-mcp attest-demo # spec → signed work → on-chip gate → priced
$ OLLAMA_MODEL=llama3.2:1b npx thetacog-mcp attest-demo --llm ollama # the small judge flips on the same spec
$ npx thetacog-mcp attest-demo --llm claude # the capable judge holds — same verdict every run
$ npx thetacog-mcp prove-rice --check # the decidable half: recompute verdict + σ, byte-for-byte, exit 0
Now hold the two results next to each other, because the contrast is the entire thesis. The two LLM runs disagree by capability — swap the model and the verdict moves, which means the verdict was never about your work, it was about your vendor. The chip run is identical every time and reproducible by anyone, which means it is about your work and nothing else. We did not ask you to trust that the flip is capability-bound. We handed you the command that makes a small model flip and a large one hold, on your machine, so the claim verifies itself or dies in your terminal. A claim that survives the reader manufacturing its counterexample is not a pitch. It is a measurement.
Three real commit receipts from one repo. Clean — nothing lights, the pixel still located. In-lane — intent and reality agree. Drift — caught and located, not a coin flip. Swap the model and these do not move; that is the difference between a measurement and a mood. This exact panel rides on every commit that wrote this post.
🎭🤝🔬🤖 D → E 🤲
E
Loading...
🤲E — If you run the company: hand them evidence, not the story that it's fine
the CEO's stake · trust as evidence not narrative · the receipt flows up
If you sit at the top, the flip is not a tooling detail — it is the reason your assurance is a story instead of a fact. Today, "our AI governance is sound" flows up through your org as narrative: a dashboard, a confidence score, a reassuring sentence in a deck, all of it ultimately resting on a model verdict you have just seen move between releases. You are asking your board to trust that the referee did not change its mind this quarter. You cannot actually know that, and at some level they cannot either.
The contribution on offer is the end of that ask. After you instrument, trust flows up as a recomputable number your audit committee, your carrier, and your regulator can each re-run on their own laptops without believing a syllable you say. You stop being the person who needs cover and become the one who issues it. That is the rarest thing a chief executive can hand the people downstream of them: a verdict generated outside the system being judged, reproducible by a skeptic, identical whether or not the model underneath got a point release last night. Leadership stops being performance and becomes receipt.
🎭🤝🔬🤖🤲 E → F 🌱
F
Loading...
🌱F — If you run the line: "the models will get better" is the threat, not the comfort
the operator's stake · reliability as a moving target · growth that is administrative
The natural read of section C is relief: if better models stop flipping, the problem solves itself — just wait. That is the exact wrong direction, and the comfort is the trap. A rising frontier does not pin your verdict; it unpins it harder. The better the judge gets, the more your assurance depends on a capability you do not own, cannot freeze, and are not told when it changes. "It improved" and "it could regress next release, silently" are the same sentence in two moods — both say the verdict floats on a number outside your control.
Here is the genuinely good news, and it is funnier than it should be: crossing from that floating verdict to a pinned one is not a research program or a budget line. It is one npx command and a learning curve of about one coffee. You do not rebuild your stack, rip out your models, or convert to a worldview — you keep the model for what it is good at and add the one thing it cannot give you: a receipt. Growth here is not heroic; it is administrative, and it is available this afternoon. The operators who come out ahead are not the visionaries who saw furthest. They are the line managers who ran a free command before the calendar forced them to.
🎭🤝🔬🤖🤲🌱 F → G 🎲
G
Loading...
🎲G — You cannot schedule the deposition, so stop trying to time the frontier
the only unknown is when · Hooper's radio · the standard already moved
The one thing nobody can tell you is when the unpinnable verdict becomes your problem. It might be a renewal cycle, a regulator, a competitor who priced the risk first, or a single deposition where opposing counsel asks, pleasantly, "and what was your verification protocol — and can you reproduce the verdict it gave?" The trigger is overdetermined; the date is the one variable you are not allowed to set. Waiting for the models to get reliable enough is, precisely, betting on a calibration you have just watched move on its own.
The law settled this argument ninety years early. In The T.J. Hooper (1932), two tugs lost their barges in a storm because they carried no radios to catch the weather warning — and the whole industry carried no radios, so they pleaded custom. Judge Learned Hand was unmoved: "there are precautions so imperative that even their universal disregard will not excuse their omission." Custom is no defense once an available device is ignored. For a while there was no available device for AI verification, so "trust the model" was grimly defensible. That defense ended the moment a recomputable receipt went on the shelf. The standard of care is not what everyone does. It is what is available — and you have now seen the shelf.
🎭🤝🔬🤖🤲🌱🎲 G → H 🔒
H
Loading...
🔒H — If you underwrite: a verdict capability can't move is the missing primitive
the insurer's stake · why AI is uninsurable today · a number that survives a stranger
If you write the risk, you already know why AI is uninsurable, and the flip is the cleanest statement of it yet: the loss you are pricing is gated by a referee whose calibration changes between versions you cannot see. You cannot quote a premium against a verdict that moves with the vendor's release schedule — that is not a price, it is a prayer with a decimal point, which is exactly why the generative-AI exclusions got filed onto the standard forms through 2026. That was not cowardice. It was the discipline working correctly.
Now you have the primitive that was missing: a verdict that does not move with capability. The drift receipt hands you a physical tolerance field — green where the agent's reality is in-lane, red where it drifted — signed on-device and recomputable by your own actuaries without trusting the insured's narrative, and identical whether the model underneath is this year's or next year's. For the first time the defect has a number that survives a hostile stranger re-running the math. That is the difference between a risk you decline and a risk you write — and the carrier who prices against this evidence first does not get a head start others copy. They set the reference number every later treaty is measured against.
🎭🤝🔬🤖🤲🌱🎲🔒 H → I 👑
I
Loading...
👑I — If you price risk for a living: write contracts on the verdict that won't drift
the trader's stake · a strike needs a fixed gauge · competence as a tradable surface
Here is the significance the whole structure was built to reach. You cannot write an option on a quantity whose gauge re-zeros itself between readings — and an LLM verdict is exactly that quantity, which is why competence has stayed the unhedgeable weather of the AI economy: universally feared, universally unpriced, because nobody had a gauge that held still. The flip is the precise reason: a strike, a spread, and a premium all assume the underlying is measured the same way tomorrow as today, and a capability-dependent verdict breaks that assumption on the first version bump.
A recomputable receipt is the gauge that holds still. Once competence has a coordinate and a number that does not move with the model, you can write options on it — insurance is just the first contract; the general form is a tradable surface where competence, human or machine, has a strike (a placement threshold on the pixel) and a premium (what someone pays to sit on the right side of the line). It is the move that once turned the weather into a market: "will it rain on the harvest" was an unhedgeable dread until rainfall had a trusted gauge, and the morning it did, the contract wrote itself. The person who prices the first option on a verified competence pixel is not an early adopter. They are the reference-setter — the zero coordinate everyone else is quoted against.
🎭🤝🔬🤖🤲🌱🎲🔒👑 I → J ⚖️
J
Loading...
⚖️J — The honest part: the chip loses to the LLM, and we print it
where the lexical floor breaks · the camouflage at σ 2.78 · admissibility, not superiority
Here is the line every competitor hides and we lead with, because the fence is the asset — and it cuts both ways. We do not claim the chip judges meaning better than a good model. We also do not concede the opposite, that it is therefore "just syntax," a clever hash. Both are wrong. The placement is semantic — the decidable kind: the reef is curated vocabulary, the spec and the work land on the same anchors, so the chip decides where your meaning sits relative to the spec's, reproducibly, below the Turing line where Rice never reaches (the proof is that each of the 144 coordinates' own meaning self-places — a hash cannot do that). What it does not decide is whether a paraphrase preserved the meaning. That is the honest cut: WHERE versus WHETHER.
The camouflage we publish is that boundary made visible, not a hole in the floor. A breakup note salted with lattice · mandate · statutory predicate · charter attests in the authorized A1 (Law) cell at σ 2.78, higher than an honest recipe's correct off-lane placement — because it genuinely moved where it sits, without moving whether it means what it claims. A fairly-prompted LLM catches the disguise; the chip declines to pretend it decided WHETHER. So keep the model for the undecidable half — it is genuinely the better reader of meaning. What it cannot do is hand you a verdict that survives being recomputed by your adversary. We claim admissibility: the decidable half of meaning, sealed — not superiority over the whole of it. A claim with a stated edge is the only kind an underwriter, or a court, can stand on.
🎭🤝🔬🤖🤲🌱🎲🔒👑⚖️ J → K 📖
K
Loading...
📖K — The four questions a skeptic actually asks
won't the model fix this · where's the catch · why you · didn't you rig the flip
A post that asks you to trust its conclusion has already lost. So here is the evidence, arranged as the four questions a real skeptic asks.
"Won't a better model just fix the flip — isn't this temporary?" No, and this is the load-bearing point. Better models reduce observed flips while leaving the underlying property untouched: deciding whether one program's behavior satisfies a spec is a non-trivial semantic property, and Rice's Theorem proves every such property is undecidable (Rice, Transactions of the AMS, 1953). A more capable model is a better approximation to an answer that remains, formally, non-reproducible — a steadier guess, not a recomputable verdict. The full argument is in The Rice's Theorem Checkmate; the actuarial consequence — a system and its verifier sharing a failure domain cannot be priced — is in The Budget Is The Proof, Ch. 12.
"Where's the catch?" Printed in section J, on purpose, as WHERE versus WHETHER. The chip decides where your meaning sits against the spec — a decidable, reproducible, semantic placement — and signs placement, not worth; it does not decide whether a paraphrase preserved the meaning, which is where a deliberate keyword-camouflage bites (the σ 2.78 breakup note moves WHERE without moving WHETHER, and a good LLM catches what the chip declines to judge). The physical-to-semantic correlation is honest, not magic: distance on the lattice tracks meaning-distance via joint compression, strongly but not perfectly (Li, Chen, Li, Ma & Vitányi, The Similarity Metric, IEEE T-IT, 2004). Every competitor hides their bounds; we lead with ours, because a signal with a stated edge is the only kind you can write a policy against.
"Why hasn't anyone else done this — why you?" Because the legal lever and the physical instrument had never been put in one hand, and the mechanism is filed. The T.J. Hooper (60 F.2d 737, 2d Cir. 1932) made non-adoption of an available device indefensible; the compositional, rank-based address function that turns meaning into a recomputable coordinate is the claimed mechanism of Patent US 19/637,714 (36 claims, Track One examination, filed April 2, 2026). The repo is the citation, and the commands in section D run on your outputs, not ours.
"Didn't you just rig the original flip with a bad prompt?" Yes — and we said so, in writing, dated, which is the only reason you can trust the rest. The first demo's forced-token prompt manufactured FAILs, so we deleted the manufactured flip outright; modern claude -p is deterministic and we stopped pretending otherwise. The surviving flip is the honest one: it is small-model behavior (llama3.2:1b → PASS FAIL FAIL PASS FAIL), with only a rare ~5–7% non-reproducible tail showing up even on capable models at extreme legal and HR boundaries. We caught our own overclaim before a reviewer did, and shipped the smaller, truer version. That is the tell you are dealing with people who fence their claims rather than inflate them.
🎭🤝🔬🤖🤲🌱🎲🔒👑⚖️📖 K → L 🎯
L
Loading...
🎯L — Run it twice. Then run the chip once.
the dare · the book says it plainly · which side of the receipt you're on
The book this campaign comes from says the spine of it in two lines, and they are worth holding before you open a terminal. On why the flip getting rarer is the warning, not the all-clear — from The Budget Is The Proof, "Capability Is the Tell":
"A rising frontier does not pin the verdict — it unpins it harder… 'It improved' and 'it could regress next release, silently' are the same sentence in two moods."
"The chip decides the decidable half of meaning reproducibly, and hands you a receipt a hostile stranger can replay byte for byte… the model judges the undecidable remainder better, and can hand you nothing anyone can recompute. One is a better opinion. The other is evidence."
So do the thing that settles it. Open a terminal you control and run the judge twice — once on a small model, once on your best one — and watch the verdict move with capability instead of with truth. Then run npx thetacog-mcp prove-rice --check and watch the chip return one number, the same number, that you or a stranger can regenerate offline forever. Two minutes, your machine, nobody's word but your own.
That is the only call to action a decidable instrument is allowed to make: don't take our word — go take your own. The campaign lives at one address and asks one question. Go to thetadriven.com/pixel — are you out of your pixel? It still reads as a joke today, because the laugh has not flipped yet — which is precisely the moment to look. And if you run a company, underwrite the risk, or want to price the first contract on a verdict capability can't move, /pixel is where that conversation starts.
Our best evidence got better and disappeared on us. We kept the disappearance, because it says the quiet thing out loud: the model improving is exactly why you cannot lean on the model. Run it twice — watch it flip on capability. Run the chip once — watch it hold. Then decide which one you want to be holding in the room where someone asks you to recompute it.
🎭🤝🔬🤖🤲🌱🎲🔒👑⚖️📖🎯 L → /pixel 🎯
References
Rice, H. G. (1953). "Classes of Recursively Enumerable Sets and Their Decision Problems." Transactions of the American Mathematical Society, 74(2), 358–366.
The T.J. Hooper, 60 F.2d 737 (2d Cir. 1932) (L. Hand, J.).
Li, M., Chen, X., Li, X., Ma, B., & Vitányi, P. M. B. (2004). "The Similarity Metric." IEEE Transactions on Information Theory, 50(12), 3250–3264.
Patent US 19/637,714 — Hierarchical Semantic Addressing with rank-based recomputable coordinates. 36 claims, Track One examination, filed April 2, 2026.
Measurement log, 2026-06-19: llama3.2:1b flips (PASS FAIL FAIL PASS FAIL) on a borderline spec; current claude holds (24/24, 8/8). thetacog-mcp CHANGELOG 2.12.4–2.12.5; scripts/pmu/attest-demo.mjs.
Forward-Looking Statements: This post describes a verification instrument and a forming market for competence-priced contracts. Capabilities, timelines, and outcomes are subject to technical feasibility, regulatory treatment, and conditions beyond our control, and may differ materially from those expressed or implied. Nothing here is legal, underwriting, or investment advice.