A few weeks ago the drift meter could already tell you when an AI agent's actions left the lane it declared. That is the useful part, and we have written about it before. This is the harder part, the part we spent this stretch on: making the instrument prove it earned its own verdict before it signs it. Because the moment you try to hand a risk number to someone who underwrites for a living, a black box that always rules is worthless to them — and an instrument that can show its work, admit where it went blind, and let you recompute the whole thing yourself is the only kind they can touch.
So this is a builder's log, written for you rather than for us. What changed is that the sensor now tries to break itself, in three ways, every single time — and signs the result of that self-sabotage into the same sealed receipt as the verdict. If you carry the risk for a deployed agent, the thing you have never been handed is an instrument that is honest about its own limits. That is the thing we built. Here is what it taught us.
The short version: a verdict is cheap — anything can produce one. We made the instrument expensive to fake. Before it signs, it deletes its own input to confirm the signal was real, swaps the meaning of the payload to confirm it is reading meaning and not bytes, and checks whether its own map even covers your codebase — then it seals all three results, plus the verdict, under one signature you can re-check without trusting the sender. An instrument that can mathematically prove its own blindness is worth more than one that claims to see everything.
A
Loading...
🪞A — We started by measuring the wrong thing, and that was the clue
the shadow · the declaration · the exposure · the gap is the product
It started as an objection to our own work. We were running the instrument over commit messages — the little notes an agent writes about what it just did — and it felt like cheating. A commit message is what the agent says it did. Measuring the note instead of the change is measuring the shadow instead of the object. You probably feel the same flinch reading it.
Then the objection inverted into the whole thesis. A commit message is not the execution — it is the Declaration of Intent, the pure semantic layer, what the agent claims it is doing. The file changes are the Actual Exposure, the physical reality of what it touched. Run both through the same lens and you are no longer measuring one thing; you are measuring the distance between what was promised and what was done. If the message maps to a benign, in-lane spot but the code streaks across a system-wide line, the agent is executing a rupture while telling a safe story. That gap has a name in every other industry — it is the difference between declared risk and actual exposure — and it is the entire basis of underwriting. We had been apologizing for the most valuable measurement we could take. For you, that is the unlock: you do not need to read an agent's mind to catch it lying. You only need to force its words and its actions through the same lens and look at the distance.
🪞 A → B ⚖️
B
Loading...
⚖️B — The atomic unit first: drift on anything, no pristine history required
the ephemeral spec · the single tremor · adoption · the seismograph before the century
The temptation was to demand the perfect setup: a complete, unbroken specification — a "constitution" for the repository — that the instrument could check every change against. That demand is fatal. Nobody has a pristine historical spec. Insist on one and your adoption is zero, because no real team can hand you the golden baseline you require.
So we built the opposite, and it is the thing that lets this survive contact with the market: the instantaneous delta. The instrument does not need a golden history to catch a single lie. It treats the commit message itself as the localized, ephemeral spec — the claim is what the agent said, the diff is what it did, and the instrument catches the rupture cold, in real time, purely on the distance between the two. What this means for you is that there is nothing to install first, no pristine record to assemble, no migration. You point it at one change and it reads. You build the perfectly calibrated seismograph first — prove it can read a single tremor without hallucinating — and only then leave it running to record the century. The unbroken record is what you accumulate, not what you must produce up front.
The longitudinal version solves itself once the atom is solid. Chain together the sealed, in-tolerance readings of single changes and you organically get the repository's constitution — its competence proven block by block. The history is the output, not the prerequisite.
🪞⚖️ B → C 🗜️
C
Loading...
🗜️C — "Couldn't you just gzip it?" — almost, and the difference is the whole moat
naive zip vs gzip-NCD · structural entropy not spelling · primary sensor · the second witness
This is the objection every engineer in the room reaches for — and the surprise is that they are half right. Compression is the correct instinct; it is literally our primary sensor. What is bankrupt is the naive version they picture: zip the message, zip the code, diff the byte sizes, call the difference drift. A single compressed-size number has no frame — it cannot tell you where anything moved, and it smears a cosmetic edit and a structural rupture into the same scalar. The fix is not to abandon compression. It is to use it the way it actually works.
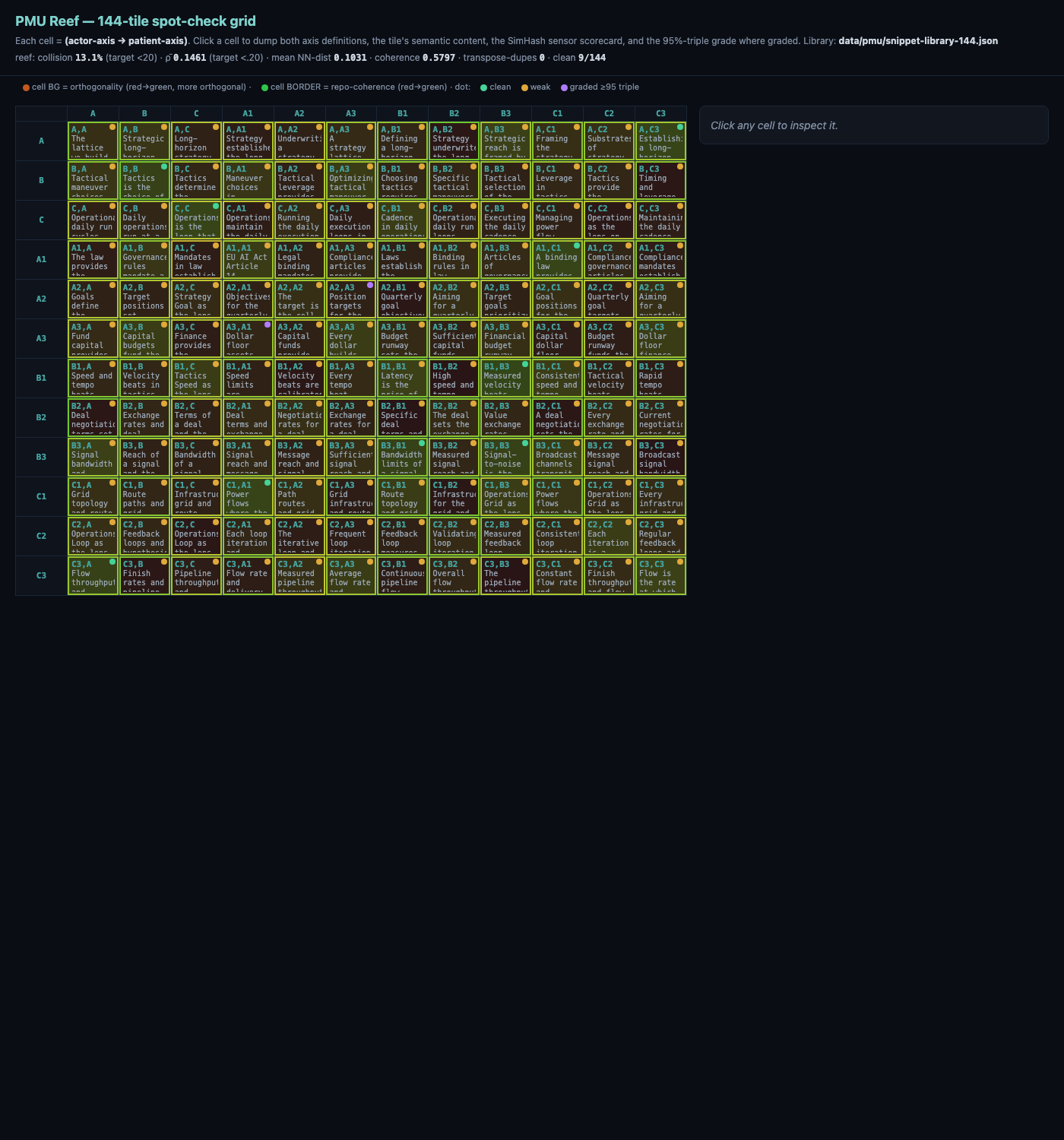
The primary sensor is gzip-NCD — Normalized Compression Distance, grounded in Kolmogorov complexity — because compression measures structural entropy: the fold of the logic, not the spelling of the words. Watch the two cases. An agent renames every variable and reshapes every loop while changing nothing it means — a line-diff screams, but compression-distance sees almost the same information and reads near-zero, correctly quiet. Now an agent swaps the meaning of a payload (the substitution test in Section E): the fold changes, the anchors that grip move, and the reading collapses. You cannot underwrite liability on a metric that confuses a renamed variable with a disabled security check — and a frameless byte-count does exactly that. We run NCD not on the whole blob but per cell, on the grounded 144-anchor lattice, so the output is a located drift — the exact lane the work jumped from and to, a floodlight on the point of fracture rather than an alarm bell in a dark room.
And we never trust a single witness. gzip-NCD is the primary — it drives both the score and the walk that lights the lattice — while a second, cheaper sensor, a SimHash lexical-overlap hash, runs beside it carrying an agreement flag. Where the two disagree — especially on the short, code-heavy fragments where lexical overlap grips poorly — the compression sensor wins; we measured that and wrote it into the rules. That dual-witness discipline is part of why the instrument is hard to fool: to spoof it you would have to fake the structure and the lexicon at once, and still land on the right lane of a fixed map.
The reason it can locate anything is the part most people miss on first look, and it is what makes the picture below more than a heatmap. Both edges of the grid are the same 144 anchors — what the work declares down one side, what the work touches across the other — and they are sorted in ShortLex order, the canonical ordering that puts semantically related anchors next to each other. That single property turns color into geometry. A cell on the diagonal is saying and doing the same thing; a cell one step off is a bleed into a neighbor lane — which, because of the ordering, is a semantically near concept, a small honest spillover; a cell far off the diagonal is a jump into an orthogonal lane — a semantically distant one, the surgeon reaching for the plumbing. So the range of green is not a palette choice — it is a measured distance. Green means the work landed where it was declared; amber means it strayed to an adjacent meaning; red means it fired in a lane with no semantic relation to the claim, and enough of it to flip the whole reading. You are not looking at a pretty render of a log file. You are looking at semantic distance drawn as space.
A real artifact, not a mockup — the lens checking its own 144 ShortLex anchors. Green where it grips, amber and red where it is thin. The axes are ordered so that neighbors mean nearby things; that is what makes the color a geometry of meaning.
🪞⚖️🗜️ C → D 🙈
D
Loading...
🙈D — The most valuable thing it does is admit when it cannot see
the false verdict · the noise read · abstain · knows when it does not know
Here is the learning that surprised us most, and it is the one to lead with if you ever show this to anyone. We hit a real case where the instrument produced a confident, severe verdict — "this change is uninsurable" — on an input where the underlying signal was, when we looked closely, noise. The reading came back at σ = -0.83, literally below random — a measurement that is statistically less ordered than coin flips, with every diagonal anchor gripping nothing. The instrument had every incentive to look decisive and rule anyway. A black box would have.
We built the opposite reflex and it is the spine of the whole thing. When the signal is not distinguishable from noise — when the read could just as easily come from a dead sensor as from clean code — the instrument now abstains. It returns undetermined, names the reason ("the lens is blind here, this is not a measurement"), and routes the spot to recalibration instead of minting a false verdict. The reason this matters more than any clever ruling: an instrument that knows when it does not know is the only kind a serious risk-taker will trust. "Always confident" is the signature of a black box. "Sometimes honestly silent" is the signature of an instrument. For you, the practical version is blunt — the dangerous monitor is not the one that occasionally misses; it is the one that never admits it missed. We made admitting it the default.
This is also a security property. A confident-but-wrong "uninsurable" verdict is not just embarrassing — once it is sealed into a token that downstream systems route money on, it is a lie with a signature. So the abstain is not politeness. It is the gate that stops the instrument from ever signing a verdict it did not actually earn.
🪞⚖️🗜️🙈 D → E 🔬
E
Loading...
🔬E — It tries to break itself before it signs
delete the signal · swap the meaning · check the coverage · all on-chip, free
The abstain raised a sharper question: how do you know the instrument was awake when it gave you a clean reading? A low drift score and a dead sensor look identical from the outside. The answer turned out to be the most important thing we built this stretch — because the underlying measurement runs on-chip in well under a millisecond, the instrument can afford to attack itself a few dozen times per reading, for free, with no AI in the loop. It runs three experiments before it signs:
One — Signal Decay. Take the input, delete half of it, then all of it, and re-measure. A live sensor reads high on the full signal and collapses to near-zero when the payload is gone. (This one taught us something we did not expect: deleting the boilerplate half of a commit message sometimes made the reading cleaner, because the noise was what we removed. We had been treating every word as equally meaningful; the instrument was actually measuring semantic density. A healthy sensor peaks on concentrated meaning and flatlines on noise — that response curve is the proof of life.)
Two — Semantic Substitution, the meaning-swap made into a live test. Take the dominant meaning in the change and forcibly swap it for an orthogonal one — replace the vocabulary of one lane with another's. If the instrument is genuinely reading meaning at the silicon level, that swap must derail the reading. If the reading survives a meaning-swap, the sensor was keying on the surface, not the meaning — and it says so. (This is also the test that retires the naive "just zip it" shortcut: a frameless compressed-size diff sails straight through a meaning-swap; our compression-distance sensor, read per lane, does not.) On code-heavy changes where the reef shares little vocabulary with the codebase, this test honestly returns "underpowered — tuning gap," which is the real, un-spun answer to "do you even have the right lens for this codebase?"
Three — Repo Calibration. Turn the lens onto the repository's recent history and report what fraction of where the team actually works the instrument can even see. When that number is, say, 36% — the instrument prints 36%, and names the 64% it is blind to, rather than pretending to full coverage.
None of this is hypothetical. Here is the self-test block from one real sealed token, lifted verbatim from the receipt it produced — the numbers below are signed into the same artifact as the verdict:
INSTRUMENT ATTESTATION — on-chip self-test(from a live sealed receipt) Signal Decay: σ 0%→26.1 · 50%→37.7 · 100%→0 — the reading responds to signal and flatlines when the payload is gone. LIVE. Semantic Substitution: baseline 37.7 → 49.8 on a meaning-swap · PARTIAL — underpowered: thin reef-vocabulary overlap with this code-heavy corpus (an honest tuning gap, not a clean pass). Repo Calibration: the lens maps 9 of the last 25 commits — 36% · center-of-mass at B1,B3. Lens health: 26-bit anchor separation · robust. Verdict: insurable, in-lane, σ 0.73 — low drift on a verified-awake sensor.
Read that block the way an underwriter would. The 36% is not a number we would ever volunteer in a pitch — it is the instrument telling on itself, in writing, sealed where it cannot be quietly deleted. And that is precisely why the in-lane verdict next to it is believable: the same instrument that just admitted it only covers a third of this repo is the one calling the change clean. A low reading from a sensor that proved it was awake is evidence. A low reading from a sensor that never tests itself is indistinguishable from a dead one.
Read the three experiments together and you have something no dashboard gives you: an instrument that, seconds before it signs, demonstrated that deleting the signal kills the reading, that swapping the meaning moves the reading, and that it is honest about how much of your world it covers. It tried to break itself and reported exactly how far it got. That is what earns a signature.
🪞⚖️🗜️🙈🔬 E → F 🔏
F
Loading...
🔏F — The receipt becomes a bearer asset you verify without trusting us
bind the triple · tamper rejects · the edited email attack · trustless
Once the instrument is honest, the next question is custody: how do you stop someone downstream from editing the verdict? Picture an enterprise that does not like an "uninsurable" reading and quietly changes the email to "insurable" before the risk committee sees it. If the artifact is just text, that attack works.
So we made the receipt a sealed bearer asset. The instrument binds the whole triple — the input it read, the lens it read through, the verdict it produced, and the three self-test results above — into one payload and signs it with an ed25519 signature. A separate verifier re-checks it and prints, in plain terms, "this verdict was provably produced by this lens on this input." We tested the exact attack: flip the sealed verdict from uninsurable to insurable and the verifier rejects it — body tampered, do not route on this token. The "edit it before the boss sees it" move is now mathematically dead. What this buys you is the thing every other AI-risk artifact lacks: you do not have to trust the company that made it. The verifier runs on your hardware, against the published signature, and the math either checks or it does not. The chip produces; anyone checks. That division of labor is the whole point, and it favors you.
🪞⚖️🗜️🙈🔬🔏 F → G 🧭
G
Loading...
🧭G — Chain the honest readings and you get a constitution, gaps and all
the ledger · the competence pixel · the honest gap · the moat that compounds
Now the readings stop being snapshots and start being a record. Each sealed, in-tolerance token is one verified block; chain them and you have an unbroken ledger — the repository's competence proven over time, the region it actually works in emerging from the data rather than asserted in a doc nobody maintains. This is the longitudinal "map of maps," and it is the part competitors cannot copy by buying the same software, because it is your history, accumulated.
The subtle thing we got right: the abstentions belong in the ledger too. When the instrument went blind and refused to rule, that is not a hole to paper over — it is an honest gap, a recorded place where the lens was owed a calibration. A constitution that records where it could not see is more trustworthy than one that claims it always could. So the record is not a wall of green; it is green where the instrument earned it and a marked, dated gap where it did not. For you, that is the difference between a compliance story that survives a hard question and one that collapses under the first "and what about that quarter?"
🪞⚖️🗜️🙈🔬🔏🧭 G → H 🔁
H
Loading...
🔁H — Closing the blind spots: the LLM proposes, the chip disposes
the vocabulary gap · extract · propose · the un-spinnable gate
The honesty of Test Three created an obligation: if the instrument admits it only covers 36% of your codebase, you have to be able to close that gap — and we learned the hard way that neither obvious approach works alone. The gap is a vocabulary problem: the lens is looking for words the codebase does not use. A purely on-chip loop cannot fix that, because the chip is a ruthless grader — it can re-weight words it already knows, but it cannot invent the missing ones. And a purely AI-driven fix is dangerous in the opposite way: a language model will happily author plausible new vocabulary that quietly destroys the map's structure.
So the loop we settled on keeps the language model strictly off the critical path. Extract the real vocabulary deterministically from the uncovered parts of the repo — the actual identifiers and terms the code uses. Propose — the model's only job is to translate those real terms into the lens, grounded in extracted ground truth, never inventing from thin air. Dispose — the proposed change is forced through the self-test battery and accepted only if coverage measurably rises, the meaning-swap test still cleanly collapses (proof we did not just dilute the lens into mush), and the map's structure survives. The language model proposes; the chip disposes, with veto power. What this means in practice is a monitor that absorbs the dialect of whatever codebase it is pointed at — while a mathematical gate, not a vibe, decides whether each change actually made it see better.
🪞⚖️🗜️🙈🔬🔏🧭🔁 H → I 🎢
I
Loading...
🎢I — What surprised us most, and why it breaks the dogma
graceful degradation · basis risk · the caged intern · the clearinghouse
The math working was the boring part. What actually surprised us — and what an outside reader called a ten out of ten for structural surprise — is how the instrument behaves precisely where modern AI is trained to bluff. Three moments stood out, and each one runs against a piece of standard engineering dogma you have probably absorbed without noticing.
One — it degrades gracefully instead of guessing. When the meaning-swap test had only enough shared vocabulary to make two swaps, the instrument did not force a Pass or a Fail to look decisive. It counted its own swaps, judged itself statistically underpowered, and returned pass: null — "a tuning gap, not a clean pass/fail." A linter forces a binary; a language model forces a confident answer; this thing reported its own insignificance and refused to rule. In an era defined by hallucinated confidence, a machine that mathematically declines to certify is the anomaly — and it is exactly the property that makes the other readings trustworthy.
Two — off-diagonal does not mean broken; it means basis risk. In one run the declared intent sat in a Strategy lane while the code actually executed one lane over, in Operations. A legacy diff would scream "massive drift." The instrument read the rigid off-diagonal bands — hundreds of green, hundreds of amber, zero red — and concluded something subtler: the code was building the plumbing for the strategy. Because those two lanes are adjacent in the ShortLex ordering, the saying-versus-doing offset is honest basis risk — the small, explainable mismatch an insurer prices rather than denies — not a rupture. That is the whole payoff of putting meaning into the geometry: the instrument can tell the difference between a surgeon reaching for the adjacent tray and a surgeon doing the plumbing, because in this map those two acts are literally different distances.
Three — the language model is a caged intern, not a co-pilot. The self-healing loop did fire a model, and it proposed a genuinely good improvement — it raised the map's separation from 0.094 to 0.266. Then the system refused to let it touch anything. The proposal went to a ledger, dry-run, blocked from the live lens until the deterministic chip gate approves it on the numbers. While the industry races to hand models write-access to production, we did the opposite on purpose: treat the model as a brilliant but untrustworthy intern whose every suggestion is gated by a check it cannot talk its way past. That cage is not a limitation; it is the precondition under which anyone underwriting the result will ever sign.
These are not three features — they are one disposition. The instrument is built to refuse to be spoofed, including by itself. That single property is what turns it from a developer tool into something an actuary can stand behind: not a better dashboard, but an automated clearinghouse where every reading is a measurement it proved it earned.
🪞⚖️🗜️🙈🔬🔏🧭🔁🎢 I → J 🚧
J
Loading...
🚧J — What we do not claim
the tuning gap · lexical not semantic · derived vs measured · against interest
You should be suspicious of how convenient all of this is to the author, so here are the bounds, stated against ourselves, because the bounded version is the one you can take to a risk committee. The coverage numbers we have measured on our own repository are honest and partial — the lens shares only thin vocabulary with a code-heavy codebase today, which is exactly why Test Two keeps returning "underpowered" and Test Three keeps printing a coverage number well under full. That is not a result we are hiding; it is a result the instrument reports on itself, and closing it is the work in section H, not a finished claim.
Two more honest edges. First, the matching that runs today is lexical-structural, not deep semantic — it reliably catches a change reaching into a lane it did not declare; it does not grade the wisdom of what it did inside its own lane. Second, an early version of a self-test reported a derived ceiling — a number computed from algebra rather than from an actual run — and when we caught it, we replaced it with a measured one, an experiment that genuinely re-runs the sensor on corrupted input. We mention it because it is the exact failure this whole post is about: an unearned number that looks like evidence. We would rather show you the seam than let a derived figure masquerade as a measurement.
Notice the shape: every claim got smaller under examination, and the instrument still stands — because its core feature is precisely that it shrinks its own claims honestly. A pitch survives enthusiasm. An instrument survives shrinkage. The fact that it flags its own tuning gaps is not the weakness in the argument; it is the argument.
🪞⚖️🗜️🙈🔬🔏🧭🔁🎢🚧 J → K ⚖️
K
Loading...
⚖️K — The three questions to ask before you believe any of this
why no alternative · why not too good · why nobody else · the citations
Why is there no software alternative — why can't a normal monitor do this? Because the "lane" an agent must stay in is a semantic property, and certifying a semantic property of an arbitrary program with another program runs straight into Rice's theorem (1953) — non-trivial semantic properties are undecidable in general. Worse, any software monitor shares the failure domain of the thing it watches: if the stack drifts or the kernel is compromised, the watcher goes down with the watched. Asking that monitor to certify the agent is asking the bank robber to write the police report. The only witness that escapes the trap is one anchored below the software, in physical execution — and a check that is non-Turing-complete, so it can be recomputed by anyone, deterministically, without sharing the failure domain it reports on.
Why isn't this too good to be true? Because we are not defeating mathematics; we are using it, and we showed you the costs. The primary sensor is compression — Normalized Compression Distance, grounded in Kolmogorov complexity — a near-parameter-free distance that reads the structural entropy of two texts, which is why it catches a meaning-swap that leaves the spelling intact. Running it fast and turning similarity into physical proximity on a fixed grid is where the second witness earns its place: a locality-sensitive hash (Charikar's SimHash, 2002), built so similar inputs land in nearby outputs — the opposite of a cryptographic hash, which destroys proximity. The compression sensor rules; the hash cross-checks; an agreement flag flies when they part. And the costs are stated in Section I: lexical overlap is the secondary read precisely because on code-heavy text it grips poorly — coverage is partial, the matching is lexical-structural not deep-semantic, and there was one derived number we caught and replaced. We quote the measured figure, never the limit.
Isn't "good enough" software oversight fine? Not once a better, independent witness demonstrably exists. There is a long doctrine here — from The T.J. Hooper (1932), where Judge Learned Hand held that an entire industry's custom is no defense when a superior available device was skipped, through the modern board-oversight cases laid out in the companion piece The Liability Has Your Name On It. The point that matters for belief: the second an independent instrument is available, continuing to rely on a dashboard the agent itself feeds stops being prudent and starts being the evidence against you.
🪞⚖️🗜️🙈🔬🔏🧭🔁🎢🚧⚖️ K → L 🎯
L
Loading...
🎯L — What it means for you, and the one move that is yours
the honest sensor · the verifiable token · the readiness question · be the one
Strip away the machinery and here is what changed, in terms you can use. The market will make you deploy agents — your competitors already are. What you have never had is an instrument that watches them and is honest about its own limits: one that abstains instead of bluffing, attacks itself before it certifies, tells you to your face how much of your world it cannot yet see, and seals the whole thing into a receipt you recompute on your own hardware. Most teams in your position will deploy anyway and quietly self-insure a risk they have not priced. The one who installs an honest instrument gets the opposite trajectory — each deployment generates evidence instead of exposure, and evidence compounds.
The move that is yours to make is small and starts this quarter. Ask the person who owns your agent deployments one question: when this agent acts, what watches it — and is the watcher made of the same software it is watching? If the answer is a dashboard the agent feeds, you now know how that reads in a deposition. If you want to see the honest version — the abstain, the self-test battery, the sealed receipt — check a signed receipt in your browser and recompute it yourself; that is the whole thesis in your hands, not ours. The deep version of the argument is in Tesseract Physics — Fire Together, Ground Together. And if you carry the budget and the risk, commission a readiness discovery — a senior look at where your agentic deployments actually sit against the missing monitor, conducted by the author of this argument, elias@thetadriven.com. The instrument's whole discipline is to never claim more than it earned. Hold the same standard for your own oversight, and be the one who asked first.