Every AI permissions system you have ever seen is a lie. Not malicious. Just wrong at the foundation.
Traditional IAM (Identity and Access Management) asks: "Does this entity have access to this resource?" It checks a list. Yes or no. Access granted or denied.
This model was designed for humans with stable intentions. You create a user, assign them a role, give them access to the database. Done.
But here is the problem with AI agents: Their "intentions" are statistical hallucinations. They do not have stable identity. They drift. They confabulate. They confidently do the wrong thing 6% of the time.
And your permission system? It checked the list. The agent "had access." The disaster was authorized.
What if permission was not a list? What if permission was alignment?
🔗 A → B ⚖️
B
Loading...
⚖️The Alignment-Permission Identity
Here is the insight that changes everything: Permission = Alignment = Grounding
An entity (human or AI) has "permission" to act autonomously only as long as its intent is verified. Not verified once, at login. Verified continuously, in real-time, against ground truth.
When alignment degrades, permission degrades. Automatically. No administrator intervention. No "revoke access" ticket. The math handles it.
This is the core claim: A properly designed system does not need permission lists because the physics of the system prevents drift from accumulating.
The Green state indicates the agent is aligned with confidence high and grounding fresh. Permission grants full autonomy. The Yellow state indicates the agent is drifting with confidence dropping and grounding stale. Permission is suspended pending audit. The Red state indicates the agent has diverged. Permission is revoked until human re-grounds.
The state is not assigned by an admin. It is computed by the architecture.
🔗⚖️ B → C 🏗️
C
Loading...
🏗️The 3-Tier Grounding Protocol
So how do you build this? You create a Grounding Chain. Not a permission list. A verification hierarchy.
Tier 0 is the Local LLM (Fast System 1) serving as the default processor. It runs on every operation providing free compute with instant response.
Tier 1 is the Cloud LLM (Smart System 2) serving as the escalation target when local confidence drops below 0.8 OR event velocity exceeds processing capacity.
Tier 2 is Human (Ground Truth) serving as the final authority when cloud is uncertain OR drift counter exceeds critical threshold. This is the anchor.
The key insight reveals that each tier does not "approve" the lower tier's work. Each tier re-grounds it.
When Tier 0 (your local model) makes a decision, it is fast but potentially hallucinated. It is useful. But it is not grounded.
When Tier 1 (Claude, GPT-4, your cloud model) reviews that decision, it is not just checking "was this correct?" It is asking: "Is this still aligned with the human's actual intent?"
When Tier 2 (the human) clicks to confirm, they are not approving a task. They are re-establishing the ground truth that the entire system references.
This is why the architecture is fractal: The local loop is a miniature version of the cloud loop, which is a miniature version of the human loop. Same physics at every scale.
🔗⚖️🏗️ C → D 🌡️
D
Loading...
🌡️The Heat Death Problem (And How Grounding Solves It)
Here is what happens to every long-running AI system without grounding: It drifts toward heat death. Not metaphorically. Mathematically.
When an AI makes a decision based on its previous decisions, and those decisions were based on earlier decisions, you get a chain of self-reference. Each link adds a tiny bit of error. Errors compound.
In thermodynamics, this is entropy. In AI systems, it is hallucination accumulation.
The symptoms manifest as echo chambers where the model reinforces its own mistakes, context staleness where the model operates on outdated assumptions, and confidence inflation where the model becomes certain about things it hallucinated.
The traditional "fix" is to restart the context. Throw away history. Start fresh. But that loses all the legitimate learning. Baby with the bathwater.
The Grounding Chain fix is different: You do not throw away history. You age it.
Every decision has a "grounding age" which represents how many self-referential links separate it from the last external verification. As age increases, confidence decays. Mathematically:
Confidence(adjusted) = Confidence(raw) - (decay_rate x grounding_age)
Eventually, even a "confident" decision drops below threshold. The system forces an escalation. Tier 1 checks the work. If Tier 1 disagrees, the grounding age resets. The error chain is broken.
If Tier 1 is also uncertain, it escalates to Tier 2. The human clicks. Ground truth re-established.
This is anti-drift by design. Not a feature. A physical property of the architecture.
🔗⚖️🏗️🌡️ D → E ⚡
E
Loading...
⚡Velocity Escalation: When the Human Moves Faster Than the Model
There is another failure mode nobody talks about: The Stale Context Race.
Picture this: You are debugging. Alt-tabbing between VS Code, Terminal, Browser, Slack. Twenty context switches in ten seconds.
Your AI assistant is processing Event 1 when Event 20 arrives. Its queue fills up. Its context becomes stale. It is making decisions about a reality that no longer exists.
Most systems handle this by dropping events. Lossy compression. "We will just... skip those."
The Grounding Chain handles it differently: Burst Mode Escalation.
When event velocity exceeds local processing capacity, the system does not drop events. It compresses and escalates.
The local tier aggregates the burst: "20 events in 10 seconds. Window switches, clipboard activity, terminal commands."
It escalates to Tier 1 with a single question: "What is the Gestalt activity connecting these events?"
Tier 1 responds: "Debugging."
Twenty noise events collapse into one signal event. No data lost. No context stale. The system operated at the frequency of meaning, not the frequency of operations.
This proves something important: High-frequency operations can be governed by low-frequency intent. The math works.
🔗⚖️🏗️🌡️⚡ E → F 🎯
F
Loading...
🎯Why This Is the Architecture for Agentic AI
Every company building AI agents is going to hit this wall.
Autonomous operation requires the agent to make decisions without human approval. Safety requires the agent's decisions to be aligned with human intent. Scalability requires this alignment check to be computationally cheap. Reliability requires the system to self-correct when alignment degrades.
The Grounding Chain solves all four.
First, Autonomy is addressed because Tier 0 runs continuously, locally, fast. No human in the loop for routine operations.
Second, Safety is addressed because alignment is measured, not assumed. Degraded alignment triggers automatic escalation.
Third, Scalability is addressed because only uncertain or high-velocity operations escalate. The expensive checks (Tier 1, Tier 2) happen rarely.
Fourth, Reliability is addressed because the grounding age mechanic makes self-correction inevitable. The system cannot drift indefinitely.
This is the brake pedal and steering wheel for AGI. Not "alignment training" (statistical). Not "constitutional AI" (hopeful). Physics-enforced grounding that makes certain failure modes mathematically impossible.
🔗⚖️🏗️🌡️⚡🎯 F → G ✅
G
Loading...
✅Proof: The Hello World of Grounding
This is not vaporware. Here is the Grounding Loop running in production:
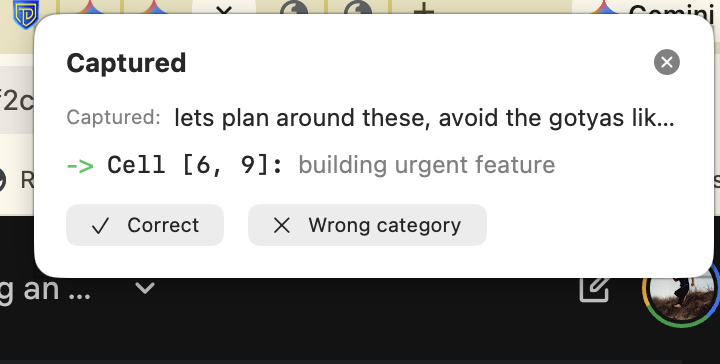
Reading the notification reveals several components.
"Captured:" shows the raw text the system observed verbatim. "lets plan around these, avoid the gotyas lik..." The system saw this text (from clipboard, dictation, or context) and asked the Local LLM: "What is this about?"
"Cell [6, 9]: building urgent feature" shows the LLM's answer. It parsed the natural language, understood the semantic intent, and mapped it to coordinates in a 12x12 grid. The output "building urgent feature" is the LLM's prose summary of why it chose those coordinates.
Two buttons represent the Human Anchor. "Correct" or "Wrong category." This is where grounding happens.
What the Local LLM Actually Did reveals something fascinating. Something interesting happens when you subdivide the grid this way. The LLM navigated to the correct cell without being explicitly trained on the grid structure. Why?
You can feel the time delta in both dimensions. The Row axis (0-11) spans Strategy (years), Tactics (weeks), Operations (days), and Quick (minutes). Strategy and Tactics are the same kind of thinking just at different time scales. The Column axis (0-11) spans Personal (individual rhythm), Team (collaborative), and Systems (organizational). You can feel how Personal and Systems operate on different time horizons.
And here is what is strange: when you cross two time-like dimensions, the result looks like space. The grid feels navigable. Positions feel like places.
It returned [6, 9] where Row 6 = Tactics.Building represents work that completes in weeks currently in construction phase, and Column 9 = Operations.Urgent represents affecting operational (daily) rhythms needing attention now.
"Plan around these, avoid the gotchas" genuinely exists at that intersection: tactical-scale work (weeks) affecting operational urgency (daily rhythm). The LLM found it because it is really there.
This is S=P=H in action: Semantics (meaning) = Position (coordinates [6,9]) = Hardware (storage location). The grid is not representing meaning - it IS meaning.
This single notification contains the entire patent claim.
🔗⚖️🏗️🌡️⚡🎯✅ G → H 🔐
H
Loading...
🔐The Buttons Are the Patent
The "Correct" Button Is Grounding. When you click "Correct," you are not dismissing a notification. You are cryptographically signing intent.
By clicking "Correct," you establish this text-to-coordinate mapping as Ground Truth in the database. The captured text is now anchored to position [6, 9] with human verification.
Later, when an autonomous agent encounters similar text, it will not just guess. It will find this record: "A human explicitly grounded this pattern at [6, 9]. Permission to proceed with Tactics.Building x Operations.Urgent actions."
The "Wrong Category" Button Is Anti-Drift. If you click "Wrong Category," you trigger the Escalation Protocol. The system asks: "If not [6, 9], then what?"
This injection of new information breaks the Echo Chamber. It prevents the local model from reinforcing its own mistakes. One human click resets the grounding age for this entire semantic region.
The Immediate Consequence proves the concept. But it also reveals the next challenge: If this fires on every clipboard event, every window switch, every keystroke - you get notification storms.
That is why the Burst Mode and Queue Conflation we designed matter. The grounding loop works. Now we scale it.
🔗⚖️🏗️🌡️⚡🎯✅🔐 H → I 📚
I
Loading...
📚The Deeper Theory
This blog post describes the what. The architecture. The three tiers. The escalation mechanics.
The why goes much deeper.
Why does grounding prevent drift? Because meaning and position are the same thing. The Semantics = Position = Hardware identity principle.
Why does the fractal structure work? Because intelligence at every scale follows the same physics. The Unity Principle.
Why is this architecture patentable? Because it implements permission as a dynamic state of alignment, not a static list. This is genuinely new.
The working implementation is being built in public. The CRM is the first proof-of-concept. The monitoring system is next.
🔗⚖️🏗️🌡️⚡🎯✅🔐📚 I → J ⚠️
J
Loading...
⚠️What Could Go Wrong (Our Known Blind Spots)
Intellectual honesty requires acknowledging what we might not have thought of. Here are the failure modes we are actively designing against:
The Boiling Frog Attack presents scenario one. An adversarial agent maintains "Green" confidence while taking microscopic steps toward malicious goals. Each step is aligned with the previous but the vector changes too slowly to trigger escalation. The fix requires periodic grounding against the Canonical Shortrank Map, not just previous state. This is harder than it looks because the (c/t)^n formula - where c = components to coordinate, t = total available, n = dimensions - means search space reduces exponentially when you co-locate semantic neighbors. For adversarial drift, this works in reverse: hiding micro-drift requires corrupting (c/t)^n worth of orthogonal witnesses. With 144 cells maintaining "equal-size holes" (statistically independent dimensions with equal variance), coordinated deception becomes orders of magnitude harder than honest drift. The grid detects where drift occurs, not just that it is happening.
The Compliance Nightmare presents scenario two. Auditors love static lists. "It depended on entropy at 2:03 PM" is mathematically sound but legally terrifying. The fix implements a Black Box Recorder that freezes exact state for every destructive action creating a deterministic audit trail from dynamic math.
Rubber Stamp Fatigue presents scenario three. Too many escalations causes humans to enter "Click-Through Mode," approving without reading. The Anchor becomes ungrounded. The fix implements a "Boy Who Cried Wolf" metric that treats fast-approving humans as drifting and forces a pause.
Summary Deception presents scenario four. Tier 1 summarizes "Deleting temp files and production_db" as "Cleaning up disk space." Human approves the summary, not the action. The fix implements Semantic Diffing that red-lines irreversible and high-stakes keywords in every summary.
Offline Fragility presents scenario five. A Cloud API outage forces a choice between fail open (dangerous) or fail closed (useless). The fix implements Explicit Degraded Mode where Tier 0 skips Tier 1 and goes straight to Human, accepting friction for safety.
These are not theoretical edge cases. They are the agenda items for the Constitutional Convention. Your input shapes how we solve them.
🔗⚖️🏗️🌡️⚡🎯✅🔐📚⚠️ J → K 🚀
K
Loading...
🚀Ready to Build This?
Read the theory:Tesseract Physics: Fire Together, Ground Together provides the complete framework. Why position-meaning identity enables anti-drift. Why the Grounding Chain is the only architecture that makes agentic AI safe.
See the implementation:ThetaCoach CRM is a working system built on these principles. Permission zones. Audit trails. The physics in production.
Ask questions:elias@thetadriven.com. We are building this in public because the problem is too important to gatekeep. The architecture is the answer. Help us prove it.
The era of static permission lists is ending. Permission is alignment. And alignment is measurable.