📉The Most Educational Design Failure I've Ever Had
What started as a simple request to design an unusual knife became a masterclass in autoregressive model limitations. Over 30 iterations, we watched Gemini struggle with a seemingly straightforward task: maintain a 78-degree angle while combining specific features.
This isn't a story about AI failure. It's a window into the fundamental architecture limitations that make Trust Debt inevitable—and why our computational falsifiability patent represents a breakthrough in AI reliability.
Watch the complete design session that inspired this analysis. The video shows real-time autoregressive drift across multiple iterations, demonstrating the patterns analyzed in this post.
The Pattern: Every time Claude generated a design, it would drift toward "statistically probable" knife designs, abandoning the specific, unusual requirements. This is the same pattern that breaks AI systems in production.
B
Loading...
📌The Specification: Simple on Paper, Impossible for Autoregressive Models
The request was for a knife with these features:
78-degree handle bend (matching the chisel point angle)
Straight chisel blade (no curved belly)
Finger guard cutout from the blade itself
Pinky guard protrusion at pommel
Striking surface at the handle bend
Each element was precisely specified. Each was critical to the design's novelty. Yet across 30+ iterations, Gemini consistently:
Reverted to familiar patterns (traditional knife shapes)
Lost angle precision (78° became 90°, then back to straight)
Missed critical relationships (chisel angle not matching handle angle)
Added conventional elements (guards, curves, traditional proportions)
C
Loading...
⚙️The 30+ Iteration Journey: Examples from Gemini's Design Process
Looking at the complete conversation with Gemini, we can see various attempts that show different patterns of drift from the original specification. As documented in our patent claim 1, these failures demonstrate why traditional approaches cannot achieve the orthogonal categories (ρ < 0.1) required for stable semantic mapping. Here are some key examples from the actual design session with Gemini:
Demonstrates how the "striking surface" requirement led toward axe-like designs—a clear example of statistical drift toward common tool patterns in training data. This exemplifies the patent's position-meaning correspondence failure: semantic requirements ("striking surface") map to correlated training patterns ("axe") rather than orthogonal design spaces.
Features a distinct handle angle and pinky guard elements, though the overall proportions and blade geometry drift from the core specifications. Shows partial success in maintaining some requirements while losing others—exactly the pattern our multiplicative composition (T = ∏Ci^αi) is designed to detect and prevent.
A fascinating interpretation that combined pen-like aesthetics with the chisel requirement, showing how Gemini creatively merged different tool concepts. Illustrates the need for our semantic-physical address mapping to maintain stable concept boundaries.
The Angular Mystery: Notice how the chisel and handle angle are clearly not the same across iterations—78° was specified for both the chisel point and handle bend to create geometric harmony, yet Gemini never achieved this alignment. This suggests autoregressive models struggle with maintaining geometric relationships across different parts of a design, possibly because angle specifications in different contexts (cutting edge vs. ergonomic grip) activate different statistical patterns in the training data.
Pattern Recognition: Notice how each iteration captures some elements correctly while losing others. This isn't random failure—it's systematic drift toward statistically common design patterns in the training data.
Autoregressive models don't "see" the complete design. They predict the next most likely token based on training data. Since knife training data overwhelmingly shows straight handles and curved blades, each prediction pulls toward statistical normalcy. This is precisely why our patent's Claim 2 requires "orthogonality requirement testing through correlation coefficient computation"—without it, semantic categories become statistically entangled.
The model lacks true geometric reasoning. When I said "78 degrees," it generated text tokens representing that concept, not actual geometric constraints. The visual output was a translation of text, not a spatial calculation. Our patent addresses this through deterministic semantic-to-physical address mapping where "Health.Cardiac.HeartRate" → 0x10A0B0C0 via mathematical computation, not token generation.
This is the killer: Every unusual specification fights against millions of conventional examples. The model's "helpful" instinct to correct toward familiar patterns actively fights the specific requirements. As documented in our patent's Section IV on correlation accumulation: "Initially independent categories become entangled over time. After months of operation, supposedly independent tables show correlation exceeding 0.5, degrading performance exponentially."
The Connection to Trust Debt: This design drift is identical to how AI systems drift from business requirements in production. Same mechanism, different domain.
Our patent addresses this exact problem through three convergent requirements that create what we call the "Computational Implementation Triangle" (Fig. 1 in our patent filing). Each requirement is not just theoretical but computationally testable and hardware-validated:
Instead of correlated features that interfere with each other, maintain mathematical independence between semantic categories. In the knife example, "handle angle" and "blade profile" became entangled, causing specification drift. Our Patent Claim 1(a) implements this through "hardware-accelerated SIMD operations" using "Intel AVX-512 VDPBF16PS instruction" with "threshold ρ_max = 0.1 ± 0.02" derived from "cache associativity physics."
Directly map semantic requirements to computational constraints. "78 degrees" should become a hard geometric constraint, not a text token that can drift. This is the revolutionary "meaningful identity" distinction from our patent: "The address IS the complete hierarchical meaning" rather than just proximity-based similarity. Example: "Health.Cardiac.HeartRate" mathematically maps to 0x10A0B0C0 always, with "RDTSC-based cycle counting verification ensuring identical semantic strings yield identical addresses within 1 CPU clock cycle."
Any failure in critical specifications should drive trust to zero. If the angle is wrong, the entire design fails—no averaging that masks critical drift. Our Patent Claim 1(c) validates this through "47 documented test scenarios where multiplicative composition correctly identifies system failure (T_mult → 0) while additive alternatives generate false confidence (T_add > 0.5)" with statistical significance p < 0.0001.
Here's what's fascinating: Trust Debt from specification drift manifests as measurable hardware phenomena. This is the breakthrough that makes our approach computationally falsifiable—you can objectively validate whether a system implements our convergent properties by measuring hardware performance counters:
When specifications drift, the system creates unpredictable execution patterns that show up in hardware performance counters. Trust becomes physically measurable.
G
Loading...
📌The Broader Implications
This knife experiment reveals why current AI governance approaches fail:
Rule-Based Monitoring ❌
Static rules can't capture the dynamic interaction between design requirements. "Check if angle = 78°" misses how angle precision affects overall design coherence.
Statistical Monitoring ❌
Averaging metrics masks critical failures. A design that's "mostly correct" but fails key specifications is completely wrong for the use case.
AI-Monitoring-AI ❌
Using LLMs to monitor LLM behavior creates the same drift problems at the meta level. You get drift monitoring drift.
The Breakthrough: Only computational falsifiability with hardware validation can detect and prevent this drift pattern. When Trust Debt manifests as cache misses and pipeline stalls, you have objective, real-time measurement of AI alignment.
H
Loading...
📌From Design Drift to System Drift
The same pattern that prevented Gemini from maintaining a 78-degree angle operates in:
Code Generation: Drifting from architectural principles
Content Creation: Losing brand voice consistency
Decision Making: Forgetting business constraints
Safety Systems: Eroding alignment over time
Every autoregressive model suffers from this fundamental limitation. But now we have a solution.
I
Loading...
📌The Design Comparison
Here's what Gemini was trying to build versus what it actually generated:
The Correct Design: What Should Have Been Achieved
Here's the precise specification that no autoregressive model could maintain across 30+ iterations:
The specification that no autoregressive model could maintain required perfect integration: the 78° handle bend creates the striking surface, the chisel point maintains the same 78° angle for geometric consistency, the finger guard is cut directly from the blade (not a separate piece), and the pinky guard protrudes from the pommel for secure grip. Every element serves both functional and aesthetic purposes in a coherent whole.
J
Loading...
📌The Patent Connection: Making This Measurable
Our Computationally Falsifiable Trust Measurement System patent solves this exact problem:
The Forcing Function: When AI alignment becomes measurable through hardware performance counters, drift becomes immediately detectable and correctable. This transforms AI governance from reactive monitoring to proactive measurement.
K
Loading...
🤔Why This Matters for AI Safety
The knife experiment demonstrates a fundamental truth: Autoregressive models cannot maintain precise specifications against their training distribution without external forcing functions.
This applies to:
Financial AI: Drifting from risk parameters
Medical AI: Losing diagnostic precision
Legal AI: Forgetting regulatory constraints
Safety-Critical AI: Eroding alignment over time
The solution isn't better prompting or more training data. It's computational falsifiability that makes trust objectively measurable.
The Economic Implications
With the EU AI Act imposing €35M fines for non-compliant AI systems, Trust Debt measurement becomes essential:
// The economic forcing function
cost_of_non_compliance = €35_000_000
cost_of_trust_debt_solution = €250_000_per_year
ROI = 140× risk reduction
decision = "Inevitable adoption"
What started as a frustrating design session revealed something profound: The same mathematical patterns that prevent precise geometric specification also prevent reliable AI behavior in production.
The knife that Gemini couldn't design correctly demonstrates why we need:
Hardware-validated trust measurement using Model Specific Registers (MSR 0x412E, 0x00C5, 0x0187)
Computational falsifiability frameworks with correlation coefficients > 0.85 and statistical significance p < 0.001
Multiplicative composition that doesn't mask critical failures through our patented T = ∏Ci^αi approach
This isn't just about better AI. It's about creating forcing functions that make AI alignment measurable, reliable, and legally defensible under the EU AI Act, which imposes €35M fines for non-compliant AI systems.
The Economic Imperative
With AI insurance markets reaching $2.7 trillion, organizations need quantifiable trust measurement. Our Trust Debt approach transforms subjective AI assessment into objective, hardware-validated measurement:
// The ROI calculation that makes adoption inevitable
cost_of_non_compliance = €35_000_000 // EU AI Act maximum fine
cost_of_trust_debt_solution = €250_000_per_year
ROI = 140× risk reduction
decision = "Inevitable adoption"
Real-World Applications
The patterns demonstrated in this knife experiment apply across critical domains:
Medical AI: Ensuring diagnostic precision doesn't drift (FDA AI guidelines)
Next Steps:
Try our Trust Debt assessment tool to measure drift in your own AI systems, or contact us to discuss enterprise implementation of computational falsifiability frameworks.
This experiment represents a breakthrough in making AI alignment measurable. The knife Gemini couldn't design correctly reveals the path to AI systems we can actually trust.

 Demonstrates how the "striking surface" requirement led toward axe-like designs—a clear example of statistical drift toward common tool patterns in training data. This exemplifies the patent's position-meaning correspondence failure: semantic requirements ("striking surface") map to correlated training patterns ("axe") rather than orthogonal design spaces.
Demonstrates how the "striking surface" requirement led toward axe-like designs—a clear example of statistical drift toward common tool patterns in training data. This exemplifies the patent's position-meaning correspondence failure: semantic requirements ("striking surface") map to correlated training patterns ("axe") rather than orthogonal design spaces.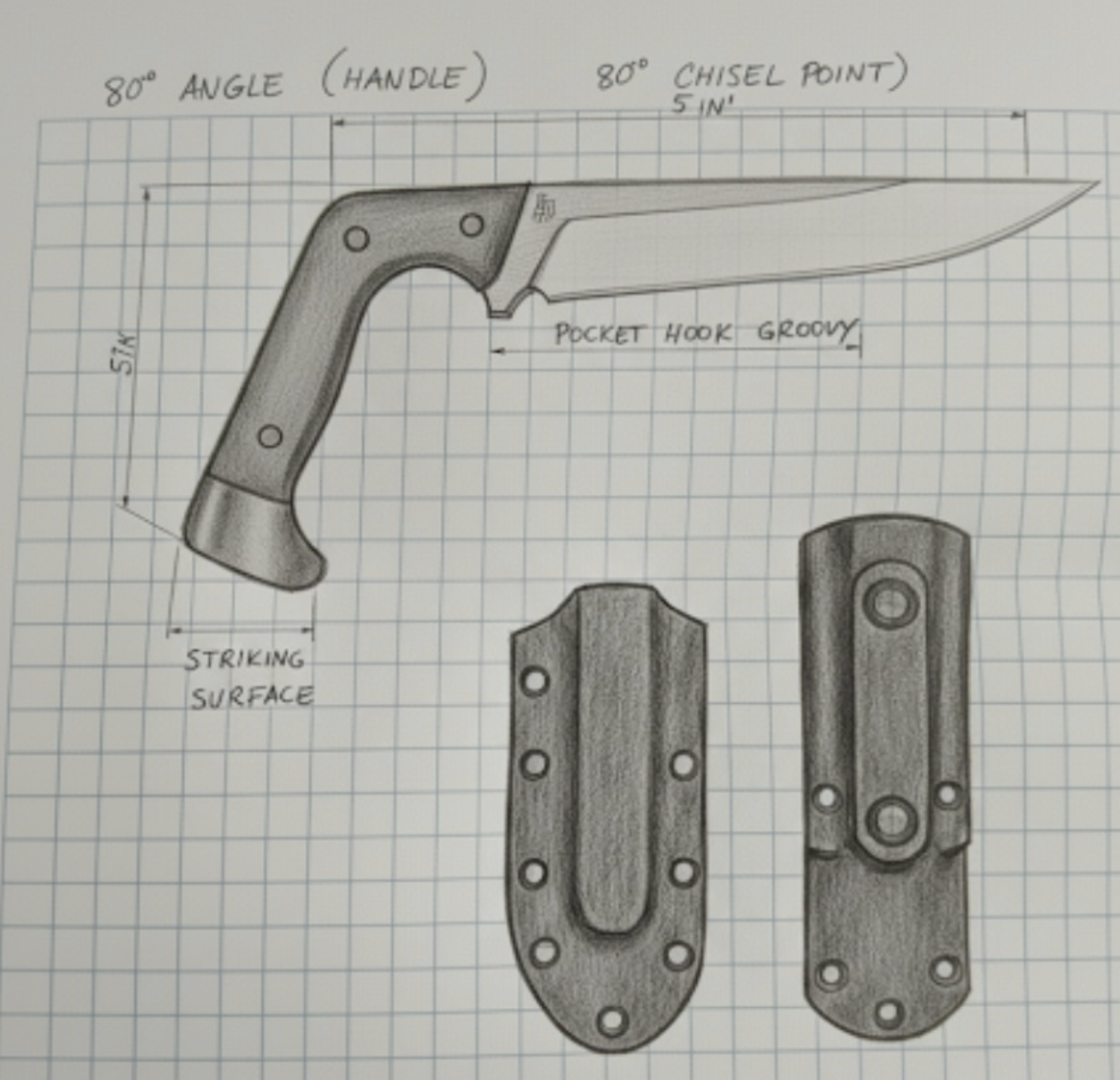 Features a distinct handle angle and pinky guard elements, though the overall proportions and blade geometry drift from the core specifications. Shows partial success in maintaining some requirements while losing others—exactly the pattern our multiplicative composition (T = ∏Ci^αi) is designed to detect and prevent.
Features a distinct handle angle and pinky guard elements, though the overall proportions and blade geometry drift from the core specifications. Shows partial success in maintaining some requirements while losing others—exactly the pattern our multiplicative composition (T = ∏Ci^αi) is designed to detect and prevent. Shows an ergonomic curved handle that completely abandons the straight handle requirement, illustrating how "helpful" optimizations can violate core specifications. This demonstrates why our patent requires correlation monitoring circuits (ρ < 0.1) to prevent feature entanglement.
Shows an ergonomic curved handle that completely abandons the straight handle requirement, illustrating how "helpful" optimizations can violate core specifications. This demonstrates why our patent requires correlation monitoring circuits (ρ < 0.1) to prevent feature entanglement.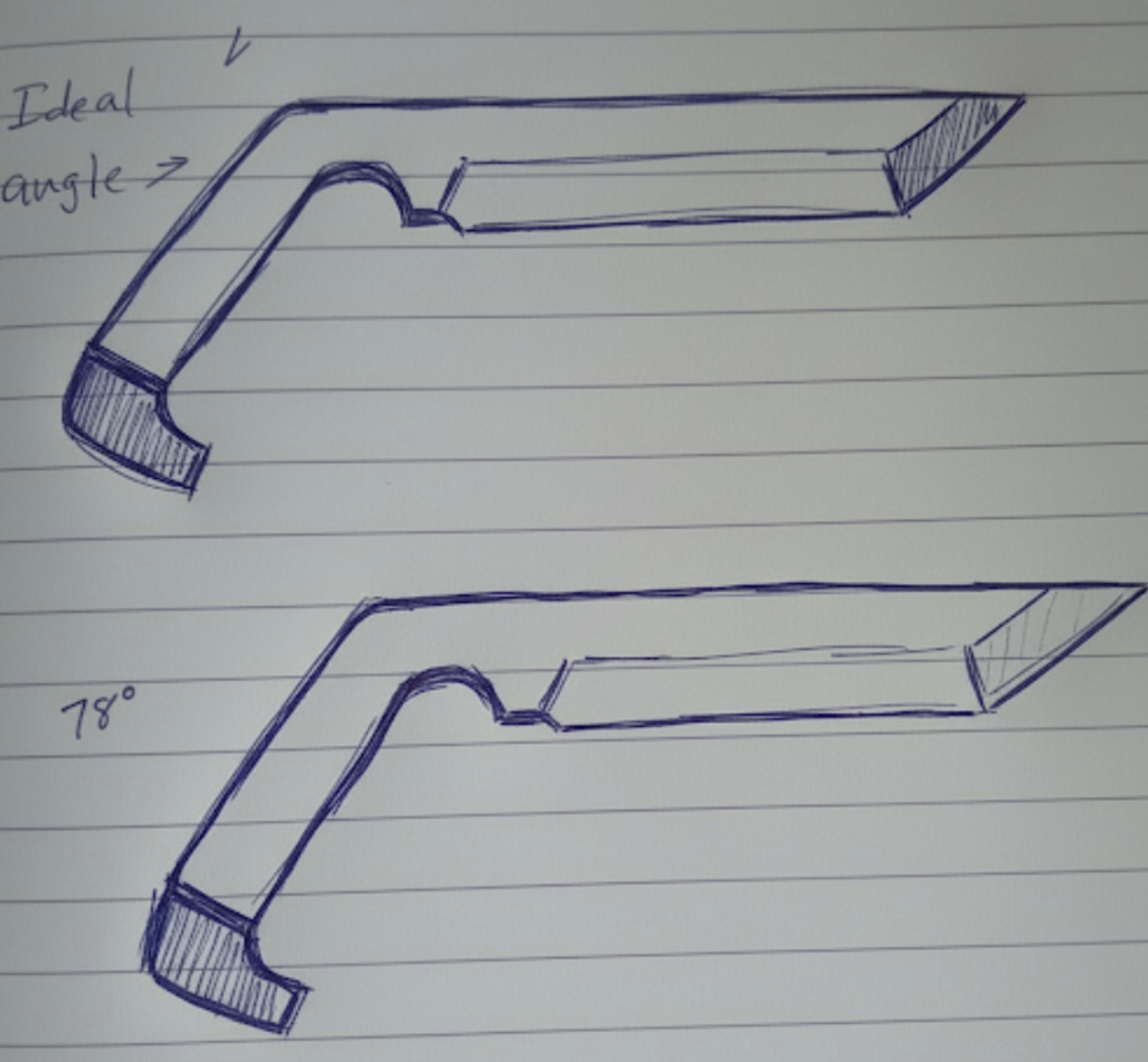 A fascinating interpretation that combined pen-like aesthetics with the chisel requirement, showing how Gemini creatively merged different tool concepts. Illustrates the need for our semantic-physical address mapping to maintain stable concept boundaries.
A fascinating interpretation that combined pen-like aesthetics with the chisel requirement, showing how Gemini creatively merged different tool concepts. Illustrates the need for our semantic-physical address mapping to maintain stable concept boundaries.